Table of Contents
-
What We Miss When We Talk About AI Models
-
Learning Architectures: How Models Actually Acquire Intelligence
-
Supervised Learning Models
-
Unsupervised Learning Models
-
Semi-Supervised Learning Models
-
Reinforcement Learning Models
-
Self-Supervised Learning Models
-
-
Functional Capabilities: What Models Are Built to Do
-
Classification Models
-
Regression Models
-
Generative Models
-
Clustering Models
-
Dimensionality Reduction Models
-
-
Structural Design: How Models Process Information
-
Neural Networks
-
Decision Trees
-
Support Vector Machines
-
Bayesian Networks
-
Ensemble Models
-
-
Application-Specific Architectures: Models Purpose-Built for Specialized Tasks
-
Natural Language Processing Models
-
Computer Vision Models
-
Recommendation Systems
-
What We Miss When We Talk About AI Models
Picture the last AI vendor meeting you sat through. Someone’s rattling off transformer architectures, convolutional networks, and recurrent models while your eyes glaze over. You nod along, pretend it makes sense, then pick whatever tool has the slickest demo.
I’ve watched this happen probably fifty times.
We’re categorizing AI models wrong. The standard technical taxonomy (neural networks vs. decision trees vs. SVMs) tells you how something works under the hood but says nothing about what it does or when you should use it. With 1 in 5 people using AI every day, understanding which types of ai models solve your problem has never been more critical.
What actually matters? How the model learns, what function it performs, how it’s structurally designed to process information, and what specific application it was built for. These four lenses give you a framework that’s useful when you’re trying to solve real marketing problems.
You don’t need a computer science degree to understand different types of ai. You need a categorization system that connects technical capabilities to business outcomes. Most resources explain what is an ai model through academic definitions when what you really need is a decision-making framework.

When you’re trying to predict customer churn, you don’t care whether the solution uses gradient boosting or neural networks. You care whether it’s built for classification tasks, how it learns from historical data, and whether it can explain its predictions to your CFO who doesn’t care about the math.
The gap between “what is an ai model” and “which AI model do I need” is where most marketing budgets get wasted. So let’s fix that.
Learning Architectures: How Models Actually Acquire Intelligence
The way an AI model learns determines everything about how you’ll use it. Data requirements, training complexity, resource costs. These all stem from the learning architecture.
When you’re deciding whether to invest in a new marketing AI tool, knowing whether it requires thousands of labeled examples or can learn from unlabeled data changes your entire implementation timeline and budget. This isn’t theoretical.
|
Learning Architecture |
Data Requirements |
Best For |
Training Complexity |
Typical Marketing Use Cases |
|---|---|---|---|---|
|
Supervised Learning |
Large labeled datasets |
Predictive tasks with clear outcomes |
Medium |
Lead scoring, conversion prediction, churn forecasting |
|
Unsupervised Learning |
Unlabeled data only |
Discovery and exploration |
Low to Medium |
Customer segmentation, anomaly detection, content clustering |
|
Semi-Supervised Learning |
Small labeled + large unlabeled datasets |
When labeling is expensive |
Medium to High |
Content moderation, product categorization with limited tags |
|
Reinforcement Learning |
Interaction environment with feedback |
Sequential decision-making |
High |
Bid optimization, dynamic pricing, personalization engines |
|
Self-Supervised Learning |
Unlabeled data (creates own labels) |
Pre-training for general capabilities |
High (initial), Low (application) |
Content generation, sentiment analysis, image creation |
1. Supervised Learning Models
Supervised learning models need a teacher. You feed them input-output pairs (this email subject line got a 23% open rate, this one got 8%) and they learn to predict outcomes for new inputs.
They’re everywhere in marketing because they solve the problems we care most about: will this lead convert? Which customers are about to churn? What’s this user’s lifetime value going to be?
But you need labeled training data, and lots of it. Someone (or something) has to tag thousands of examples before the model can learn patterns. For conversion prediction, that means historical data showing which leads became customers. For sentiment analysis, you need text samples manually coded as positive, negative, or neutral.
When you’ve got the data, supervised models deliver consistent, measurable results. They’re particularly strong for:
-
Lead scoring systems that prioritize sales outreach
-
Email subject line performance prediction
-
Customer segmentation based on purchase behavior
-
Fraud detection in ad click patterns (especially important if you’re running paid ads at scale)
-
Pricing optimization based on historical conversion data
The investment in labeling pays off when you’re solving repetitive, high-volume prediction tasks. If you’re making the same type of decision thousands of times (which ad to show, which email to send, which lead to call first), supervised learning models justify their upfront cost.
I’ve seen teams try to skip the labeling step. It never works. You can’t shortcut this part.
2. Unsupervised Learning Models
Nobody tells unsupervised models what to find. They dig through unlabeled data looking for patterns, clusters, and anomalies you didn’t know existed.
This is how you discover that your customer base naturally segments into five distinct behavioral groups you never designed for. Or that a subset of your website traffic follows a completely different browsing pattern than everyone else.
Unsupervised learning shines when you’re exploring rather than predicting. You don’t need labeled training data (which is expensive and time-consuming to create), but you also don’t get specific predictions. Instead, you get insights about structure and relationships.

Marketing applications include:
-
Customer segmentation without predefined categories
-
Anomaly detection in campaign performance (like when your click-through rate suddenly tanks and you need to know why)
-
Topic modeling to understand what your audience talks about
-
Market basket analysis revealing which products get purchased together
-
Content clustering to identify thematic patterns in user-generated content
The issue is interpretability. When an unsupervised model tells you there are seven distinct customer clusters, it can’t automatically tell you what defines each cluster or what to do about them. You still need human analysis to translate patterns into strategy.
Use these models when you’re genuinely exploring, not when you already know what question you’re trying to answer. They’re discovery tools, not decision engines. I’ve had clients try to use them for prediction and then wonder why the results are vague.
3. Semi-Supervised Learning Models
Semi-supervised models work with what you’ve got: a small set of labeled examples and a mountain of unlabeled data. They use the labeled portion to guide learning while extracting additional patterns from the unlabeled majority.
Labeling data is expensive. Getting humans to tag 50,000 customer support tickets by topic costs real money and time. But you might already have 2,000 tagged examples from a pilot project.
Semi-supervised learning builds useful models without labeling everything. The model learns from your labeled examples, then uses those patterns to extract additional structure from unlabeled data, gradually improving its understanding.
Here’s where it works:
-
Content moderation when you’ve tagged some problematic posts but not your entire archive
-
Product categorization when you’ve classified some items but have thousands more
-
Sentiment analysis with limited labeled reviews but extensive unlabeled feedback
-
Image tagging when you’ve manually labeled a subset of your visual content
The performance sits between supervised and unsupervised approaches. You won’t match the accuracy of fully supervised models trained on comprehensive labeled datasets, but you’ll dramatically outperform unsupervised methods when you need predictive power.
This is the pragmatic middle path when perfect data is too expensive but you still need actionable predictions. Last month a client came to us after spending three months trying to label everything. We switched them to semi-supervised and had a working model in two weeks.
4. Reinforcement Learning Models
Reinforcement learning models learn by doing. They take actions, observe results, and adjust their strategy to maximize cumulative rewards over time.
Unlike supervised models (which learn from historical examples) or unsupervised models (which find patterns), reinforcement models actively experiment. They’re optimizing a sequence of decisions, not just predicting a single outcome.
Perfect for marketing scenarios where decisions cascade and context changes:
-
Programmatic ad bidding that adjusts in real time based on performance
-
Email send-time optimization that learns through continuously learning systems, adjusting strategy to maximize cumulative rewards
-
Content recommendation sequences that adapt based on engagement
-
Dynamic pricing that responds to competitor moves and demand signals
-
Chatbot conversation flows that improve through user interactions
The complexity is higher than other learning approaches. You need to define what “reward” means (is it clicks? conversions? revenue? lifetime value?), and the model needs room to experiment, which means accepting some suboptimal decisions during the learning phase.
If your marketing decision affects future opportunities (showing this ad now means you can’t show that one later), reinforcement models understand those tradeoffs in ways supervised models don’t. The investment makes sense for high-frequency, high-value decision-making where small improvements compound dramatically over time.
But look. Most marketing teams don’t need reinforcement learning. It’s overkill unless you’re running sophisticated bidding systems or personalization engines at serious scale.
5. Self-Supervised Learning Models
Self-supervised models create their own training data. They take unlabeled content and generate prediction tasks from it: mask out words and predict what’s missing, hide parts of images and reconstruct them, or predict what comes next in a sequence.
This is how large language models learn language patterns without anyone manually labeling billions of sentences. The model learns by predicting masked words, with the original text serving as the “correct answer.”
For marketers, this is why modern AI tools work so well with minimal custom training. The model has already learned massive amounts about language, images, or patterns before you ever apply it to your specific use case.
You’re using self-supervised models when you:
-
Generate marketing copy with tools like ChatGPT or Claude
-
Create images with DALL-E or Midjourney
-
Transcribe audio with Whisper
-
Analyze sentiment without training a custom model
-
Extract key phrases from customer feedback
You don’t need domain-specific labeled data to get started. The model’s self-supervised pre-training gives it broad capabilities you can apply immediately, then fine-tune with smaller amounts of your own data if needed.
This learning architecture is why AI capabilities have exploded recently. Self-supervised approaches let models learn from the entire internet rather than requiring humans to label everything first.
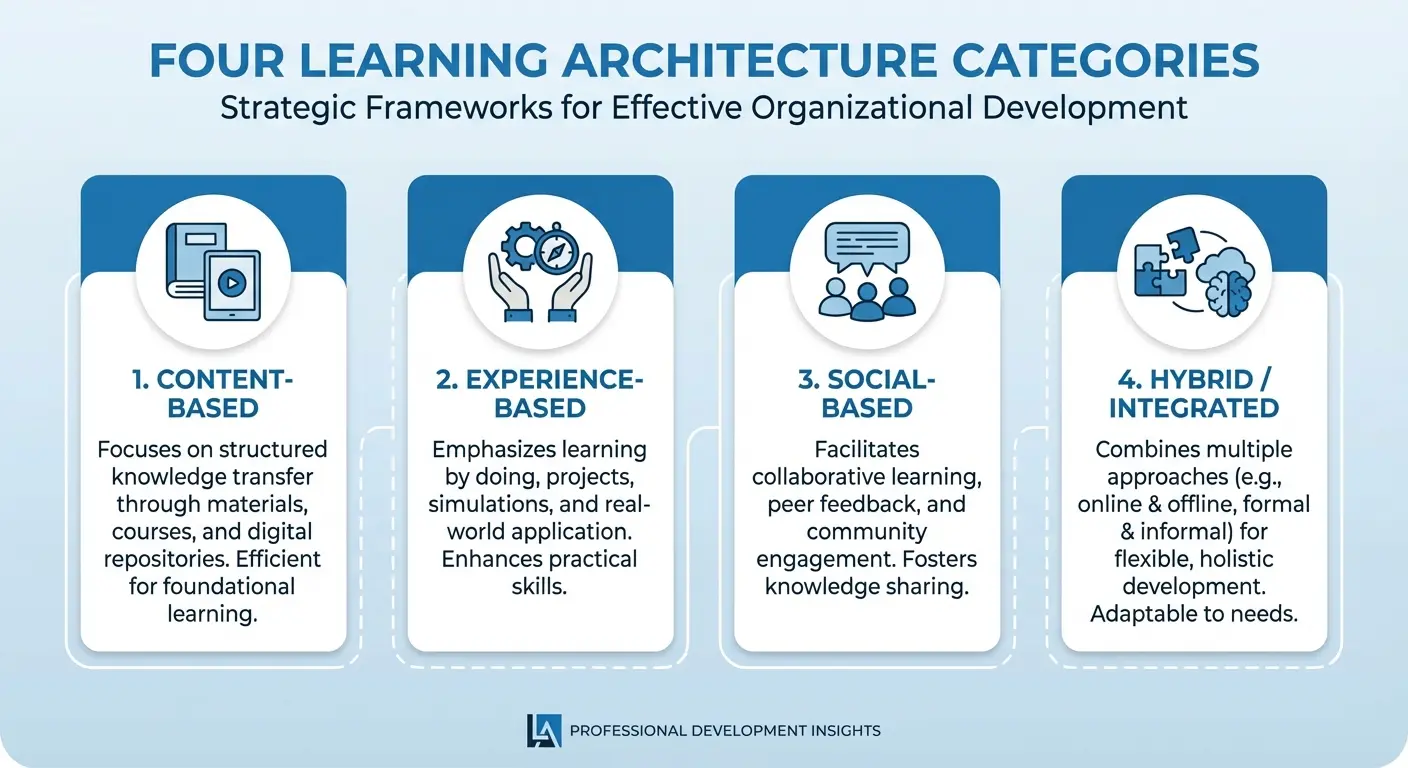
Functional Capabilities: What Models Are Built to Do
Forget about how a model is built for a second. What does it do?
Does it classify things into categories? Predict numbers? Generate new content? Discover hidden patterns?
Functional capability matters more than architectural details when you’re matching solutions to problems. You don’t care about the underlying math when you need to predict customer lifetime value. You care that the model performs regression, not classification.
We’ve organized different types of ai and ai types by their core function because that’s how you should evaluate whether a tool solves your specific problem.
6. Classification Models
Classification models answer categorical questions. Will this lead convert (yes/no)? Which customer segment does this user belong to (A, B, C, D, or E)? Is this email spam or legitimate?
They’re the foundation of marketing automation because so many of our decisions are categorical. You’re not predicting a number (that’s regression), you’re assigning something to a bucket.
Binary classification handles two-category decisions:
-
Churn prediction (will churn / won’t churn)
-
Email engagement (will open / won’t open)
-
Lead qualification (qualified / not qualified)
-
Content moderation (appropriate / inappropriate)
Multi-class classification handles multiple categories:
-
Customer lifetime value tiers (high / medium / low / minimal)
-
Product recommendation categories
-
Content topic classification
-
Customer service routing (billing / technical / sales / other)
-
Ad creative performance tiers
The output is a category assignment, often with a confidence score. The model might say this lead is 73% likely to be in the “high value” category and 27% likely to be “medium value.”
What makes classification powerful for marketing is its direct connection to action. Once you know the category, you know what to do: call high-value leads first, send personalized emails to engaged segments, route support tickets to the right team.
You’re probably using classification models already in your CRM, email platform, and ad tools. They’re everywhere because categorization drives automation.
7. Regression Models
Regression models predict numbers. Not categories, not yes/no answers, but numerical values: $847 in predicted lifetime value, 2.3% expected conversion rate, 156 clicks forecasted for this ad group.
When the specific number drives your decision, you need regression. You don’t just want to know if a customer is “high value” (that’s classification), you want to know their predicted lifetime value is $2,400 so you can calculate exactly how much to spend acquiring them.
Marketing applications include:
-
Customer lifetime value prediction for acquisition cost optimization
-
Revenue forecasting for budget planning
-
Conversion rate estimation for A/B test sample size calculations
-
Bid amount optimization in programmatic advertising
-
Sales pipeline value prediction
-
Website traffic forecasting for capacity planning
The output is continuous rather than discrete. Instead of “high/medium/low,” you get “$1,847.” Instead of “will convert/won’t convert,” you get “23% probability of conversion.”
Regression models power the financial side of marketing analytics. When you’re building ROI projections, allocating budgets across channels, or calculating payback periods, you need numerical predictions that feed directly into spreadsheets and financial models.
The distinction from classification matters when choosing tools or building systems. If your vendor says their AI does “prediction,” ask whether it’s categorical classification or numerical regression. They solve different problems and require different evaluation approaches.
I’ve sat through too many vendor demos where they blur this distinction. Make them clarify.
8. Generative Models
Generative models create new content. They don’t analyze, classify, or predict from existing data. They generate text, images, audio, video, or code that didn’t exist before.
This is the AI category that’s transformed marketing workflows in the past two years. Generative AI models, like ChatGPT, create new and meaningful content by leveraging extensive training data and predictive techniques, fundamentally changing how marketing teams approach content production. Understanding different types of ai models and what are the different types of ai becomes important when evaluating these tools.
We’re using generative models to:
-
Draft email copy, ad headlines, and landing page content
-
Create product images, social media graphics, and display ads
-
Generate video scripts and storyboards
-
Produce personalized content variations at scale
-
Develop creative concepts and brainstorm campaign ideas
The underlying technology (often transformer architectures or diffusion models) matters less than understanding what these models can and can’t do reliably.

They excel at:
-
Producing first drafts that humans refine
-
Creating variations on established themes
-
Generating volume when you need hundreds of personalized versions
-
Handling routine content production tasks
-
Exploring creative directions quickly
They struggle with:
-
Maintaining brand voice consistency without fine-tuning
-
Fact-checking and accuracy (they generate plausible content, not necessarily true content)
-
Understanding strategic context beyond their training data
-
Replacing human creative judgment and strategic thinking
The workflow shift is significant. Instead of creating everything from scratch, you’re now editing, directing, and curating AI-generated options. This changes team structure, skill requirements, and production timelines.
Generative models are tools, not replacements. They amplify creative capacity but still require human oversight for quality, brand alignment, and strategic coherence. The marketers winning with generative AI treat it as a collaborative partner, transforming marketing workflows through AI-powered content tools that create rather than analyze.
9. Clustering Models
Clustering models find groups in your data without being told what groups to look for. They examine similarities and differences, then organize data points into clusters where members are more similar to each other than to members of other clusters.
This differs from classification in a way that matters: you’re not predicting membership in predefined categories. You’re discovering what categories naturally exist in your data.
Marketing applications reveal hidden structure:
-
Customer segmentation based on behavior patterns, not demographic assumptions
-
Product grouping by purchase relationships rather than catalog categories
-
Content clustering to understand thematic patterns in user-generated content
-
Market segmentation based on competitive positioning
-
Campaign performance grouping to identify distinct success patterns
The number of clusters isn’t predetermined. Different algorithms and parameters will suggest different groupings, and you need business judgment to decide which segmentation is most useful.
What you get is exploratory insight, not predictive power. The clustering model tells you “these 2,400 customers behave similarly and distinctly from these other 3,100 customers.” It doesn’t automatically predict which cluster a new customer will join or what defines each cluster’s behavior.
You still need analysis to interpret clusters: what makes cluster A different from cluster B? Why does this grouping matter for marketing strategy? What should we do differently for each segment?
Clustering works best when you suspect your current segmentation is wrong or incomplete. If your demographic segments don’t predict behavior well, clustering might reveal behavioral segments that do.
10. Dimensionality Reduction Models
Dimensionality reduction models take complex data with hundreds or thousands of variables and compress it into a simpler representation that captures the most important patterns.
This sounds abstract until you’re trying to understand customer behavior tracked across 247 different touchpoints, or analyzing campaign performance across 83 variables. You can’t visualize 247 dimensions or intuitively understand which variables matter.
Dimensionality reduction solves this by finding the underlying patterns. Maybe those 247 touchpoints really represent five core behavior patterns. Maybe those 83 campaign variables reduce to three drivers of performance.
Marketing applications include:
-
Simplifying customer journey analysis when you track dozens of touchpoints
-
Feature engineering for predictive models (reducing hundreds of potential inputs to the most predictive few)
-
Visualization of complex customer segments in two or three dimensions
-
Identifying which marketing metrics drive outcomes versus which are just noise
-
Compressing large datasets for faster processing in other models
The most common techniques (PCA, t-SNE, UMAP) work differently but share the same goal: preserve the meaningful patterns while eliminating redundant or irrelevant complexity.
You’re typically using dimensionality reduction as a preprocessing step rather than an end goal. It makes other analysis possible by taming complexity. When your analytics platform shows you a two-dimensional visualization of customer segments that were originally defined by 50+ behavioral variables, dimensionality reduction made that visualization possible.
Instead of drowning in hundreds of metrics, you identify the handful that explain variance in outcomes. This drives better decision-making by eliminating noise.
Structural Design: How Models Process Information
Architecture determines how a model transforms raw inputs into useful outputs. The structural design affects interpretability, training requirements, computational costs, and performance characteristics in ways that matter for marketing implementation.
Understanding these types of ai models and different types of ai models helps you evaluate vendor solutions and internal capabilities more effectively.
|
Structural Design |
Interpretability |
Data Requirements |
Computational Cost |
Best Use Cases |
|---|---|---|---|---|
|
Neural Networks |
Low (black box) |
High (thousands+ examples) |
High |
Complex pattern recognition, image/text processing |
|
Decision Trees |
High (traceable logic) |
Medium |
Low |
Explainable decisions, rule extraction |
|
Support Vector Machines |
Low to Medium |
Medium (works well with limited data) |
Medium to High |
Text classification, high-dimensional spaces |
|
Bayesian Networks |
High (causal structure) |
Medium |
Medium to High |
Attribution modeling, causal inference |
|
Ensemble Models |
Medium |
Medium to High |
Medium to High |
Production systems requiring accuracy |
11. Neural Networks
Neural networks process information through layers of interconnected nodes, each applying mathematical transformations to detect patterns at different levels of abstraction.
They’re the architecture behind most modern AI breakthroughs: large language models, image recognition, recommendation engines, and voice assistants all use neural network variants.
Why they matter for marketing: neural networks excel at finding complex, non-linear patterns in messy data. They can learn intricate relationships between hundreds of input variables and outcomes without you explicitly programming those relationships.
This makes them powerful for:
-
Image recognition in user-generated content moderation
-
Natural language understanding in chatbots and sentiment analysis
-
Complex pattern recognition in customer behavior prediction
-
Recommendation systems that personalize content and products
-
Voice and speech recognition in customer service automation
The tradeoffs are significant. Neural networks require substantial training data (often thousands or millions of examples) and computational resources. They’re also “black boxes” that don’t easily explain their reasoning, which creates problems when you need to justify decisions to stakeholders or comply with regulations.
Different neural network architectures (convolutional networks for images, recurrent networks for sequences, transformers for language) excel at different tasks. You don’t need to understand the architecture details, but you should know that “neural network” is a broad category with specialized variants.
Most marketing AI tools you’re already using run on neural networks under the hood. The question isn’t whether to use them, it’s whether the specific implementation solves your problem better than alternatives.
12. Decision Trees
Decision trees make predictions by asking a series of yes/no questions, branching at each step until reaching a conclusion. Think of them as flowcharts that learned themselves from data rather than being manually designed.
They’re refreshingly interpretable. You can trace the decision path: “If email open rate > 15% AND website visits > 3 AND days since last purchase < 30, THEN predict high conversion probability.”
This transparency matters when:
-
You need to explain predictions to non-technical stakeholders
-
Regulatory requirements demand explainable decisions
-
You’re debugging why certain predictions seem wrong
-
You want to extract business rules from data
-
Trust and buy-in require understanding the reasoning
Marketing applications where interpretability is necessary:
-
Lead scoring systems where sales teams need to understand why leads are prioritized
-
Credit and financial decisions with regulatory oversight
-
Customer service routing where agents need to understand the logic
-
Marketing mix modeling where executives want clear cause-effect relationships
Decision trees handle both numerical and categorical data naturally, work with missing values reasonably well, and require less data preprocessing than neural networks.
The limitation is they’re prone to overfitting (learning noise rather than signal) when they grow too complex, and they struggle with subtle, complex patterns that neural networks capture easily.
Single decision trees are rarely used alone in production systems. Instead, they’re combined into ensemble methods (covered next) that maintain some interpretability while dramatically improving accuracy.
13. Support Vector Machines
Support vector machines find the optimal boundary between categories. Instead of just separating classes, they maximize the margin between them, creating the most solid separation possible given your training data.
They work particularly well in high-dimensional spaces (lots of features relative to examples) and when you have clear separation between categories but limited training data.
Marketing applications where SVMs excel:
-
Text classification with limited labeled examples (spam detection, content categorization)
-
Customer segmentation when you have many behavioral features but relatively few customers
-
Image classification for brand logo detection in user-generated content
-
Sentiment analysis on customer feedback
-
Fraud detection in advertising click patterns
SVMs handle situations where you have 50 features but only 200 training examples better than neural networks, which would overfit badly. They’re also less prone to being fooled by outliers than some other approaches.
The downsides: they’re computationally expensive with large datasets, don’t naturally handle multi-class problems (though extensions exist), and like neural networks, they’re not particularly interpretable.
You’re most likely to encounter SVMs in specialized classification tasks where data is limited but feature-rich. They’re not the default choice anymore (neural networks and ensemble methods have largely displaced them for general use), but they still shine in specific scenarios.
If you’re working with a vendor who mentions SVMs, they’re probably dealing with text classification or a scenario with limited training data. Ask why they chose this approach over alternatives.
14. Bayesian Networks
Bayesian networks model probabilistic relationships between variables, explicitly representing how different factors influence each other and propagating uncertainty through the system.
Unlike other model types that focus purely on prediction, Bayesian networks encode causal structure. They tell you not just that email open rate and conversion are correlated, but how changes in one affect the probability of the other given everything else you know.
This makes them uniquely valuable for:
-
Marketing attribution modeling that accounts for channel interactions
-
Customer journey analysis understanding how touchpoints influence each other
-
A/B test analysis incorporating prior knowledge and uncertainty
-
Decision-making under uncertainty where you need to quantify confidence
-
Causal inference when you can’t run controlled experiments
Bayesian networks excel when you need to reason about “what if” scenarios. What happens to conversion probability if we increase email frequency but reduce ad spend? The network propagates those changes through the causal structure.
They also handle missing data elegantly by reasoning about probability distributions rather than requiring complete information for every prediction.
The tradeoffs: they require more upfront work to specify the structure (which variables influence which others), they’re computationally expensive for large networks, and they need expertise to build and interpret correctly.
You’re most likely to encounter Bayesian approaches in attribution modeling and marketing mix modeling where understanding causal relationships matters more than pure predictive accuracy.
15. Ensemble Models
Ensemble models combine multiple individual models to produce better predictions than any single model could achieve alone. Instead of picking one approach, you use several and aggregate their outputs.
This is why ensemble methods (particularly random forests and gradient boosting) dominate real-world machine learning applications. They consistently outperform single models across diverse problems.
The main ensemble approaches:
Random Forests combine hundreds of decision trees, each trained on different subsets of data and features. They vote on the final prediction, smoothing out individual tree errors while maintaining reasonable interpretability.
Gradient Boosting builds trees sequentially, with each new tree focusing on correcting the errors of previous trees. This creates highly accurate models that often win machine learning competitions.
Stacking combines different model types (neural networks, decision trees, SVMs) by training a meta-model to optimally weight their predictions.
Marketing applications where ensembles excel:
-
Customer lifetime value prediction requiring high accuracy
-
Conversion probability scoring across diverse customer segments
-
Fraud detection balancing false positives and false negatives
-
Demand forecasting incorporating multiple signal types
-
Churn prediction where accuracy directly impacts retention ROI
Ensembles handle messy real-world data better than single models. They’re more resilient to outliers, missing values, and noisy features. They also reduce overfitting by averaging out individual model quirks.
Most production marketing AI systems use ensemble methods under the hood, even if vendors don’t advertise it. When evaluating tools, ask what modeling approach they use. “Gradient boosted trees” or “random forest” signals a mature, production-ready system requiring the kind of advanced analytics for strategic growth that ensemble methods consistently deliver.
Application-Specific Architectures: Models Purpose-Built for Specialized Tasks
Some problems need specialized solutions. General-purpose models struggle with the unique challenges of language, vision, or personalization, so we’ve developed architectures optimized for specific domains.
These types of ai models and different ai approaches outperform general methods because they’re built around the particular structure and requirements of their target domain. Understanding artificial intelligence types and artificial intelligence models in these specialized contexts helps you select the right tools for domain-specific challenges.
16. Natural Language Processing Models
Natural language processing models are purpose-built to handle the unique challenges of human language: context, ambiguity, semantic meaning, grammatical structure, and the fact that word order matters.
General-purpose models struggle with language because “bank” means different things in “river bank” versus “savings bank,” and “the dog bit the man” means something completely different from “the man bit the dog” despite using identical words.
Modern NLP models (particularly transformer-based architectures like BERT, GPT, and their variants) have revolutionized marketing capabilities. A growing body of research published in Quanta Magazine has found that different artificial intelligence models, including language and vision systems, can develop similar representations even when trained on entirely different data types, suggesting these models are converging on shared understandings of reality.
Marketing applications include:
-
Content generation for ads, emails, landing pages, and social posts
-
Sentiment analysis across customer reviews, social mentions, and support tickets
-
Chatbots and conversational AI for customer service
-
Text summarization of customer feedback and market research
-
Keyword extraction and topic modeling from unstructured content
-
Language translation for international campaigns
-
Content optimization and SEO analysis
These models understand context through attention mechanisms that weigh the importance of different words relative to each other. They’ve been pre-trained on massive text datasets, giving them broad language understanding you can apply to specific marketing tasks with minimal additional training.
The shift from rule-based NLP to neural language models has been dramatic. Five years ago, chatbots followed rigid scripts. Now they understand intent, handle variations, and generate contextually appropriate responses.
You’re using NLP models when you work with any AI writing assistant, sentiment analysis tool, chatbot platform, or voice assistant.
17. Computer Vision Models
Computer vision models process visual information: images, videos, and visual patterns. They’re built with architectures (particularly convolutional neural networks) specifically designed to handle the structure of visual data.
Why visual data needs specialized models: images contain spatial relationships, hierarchical features (edges combine into shapes, shapes into objects), and patterns that repeat across different positions. General-purpose models don’t naturally capture these properties.
Marketing applications have expanded dramatically:
-
User-generated content moderation detecting inappropriate images at scale
-
Visual search allowing customers to find products by uploading images
-
Brand logo detection across social media and web content
-
Product recognition in influencer posts for partnership tracking
-
Creative analysis identifying which visual elements drive engagement
-
Automated image tagging for digital asset management
-
Quality control for product photography
-
Facial recognition for demographic analysis (where legally permitted)

Computer vision models can now identify objects, understand scenes, detect emotions in faces, read text within images, and even generate new images from text descriptions.
You can now automate visual tasks that previously required human review. Screening thousands of user-submitted photos for brand campaigns, tracking logo appearances across the internet, or analyzing which product angles drive conversions all become scalable.
The limitations remain around nuance and context. Computer vision models can identify that an image contains a person holding a product, but understanding the emotional tone or cultural context still requires human judgment.
18. Recommendation Systems
Recommendation systems are architected specifically to predict what individual users will find valuable, combining information about user behavior, item characteristics, and contextual factors.
They’re not just classification or regression models applied to preference data. They’re purpose-built systems that handle unique challenges: cold start problems (recommending to new users with no history), scalability (generating personalized recommendations for millions of users across millions of items), and the exploration-exploitation tradeoff (balancing familiar recommendations with discovery).
The main architectural approaches:
Collaborative filtering finds patterns in user behavior across your entire customer base. Users who liked items A and B also liked item C, so we recommend C to similar users.
Content-based filtering recommends items similar to what a user has engaged with previously, based on item attributes rather than other users’ behavior.
Hybrid systems combine both approaches, often adding contextual factors like time, device, location, and recent browsing behavior.
Marketing applications where recommendation systems drive measurable impact:
-
E-commerce product recommendations increasing average order value
-
Content recommendation engines boosting engagement and time on site
-
Email personalization selecting which products or content to feature
-
Ad targeting determining which creative to show each user
-
Next-best-action systems in marketing automation
-
Dynamic website personalization adapting content to individual visitors
The business impact is real. Effective recommendation systems typically increase conversion rates 10-30% and significantly boost customer lifetime value by improving relevance.
Modern recommendation systems increasingly use deep learning architectures that can capture complex, non-linear patterns in user behavior. They’re also becoming more context-aware, adapting recommendations based on time of day, device, recent search queries, and real-time behavior signals.
The challenge isn’t building a basic recommendation system (most platforms offer this out of the box). It’s optimizing for your specific business goals, handling the cold start problem gracefully, and balancing personalization with discovery to avoid filter bubbles.
Connecting Model Types to Marketing Outcomes
You’ve now seen 18 different types of AI models across four distinct lenses: how they learn, what they do, how they’re built, and what they’re specialized for.
The framework matters because picking the wrong model type wastes budget and time. When you’re evaluating AI vendors or building internal capabilities, you need to match your specific problem to the right combination of model characteristics. Understanding what are the different types of ai models and types of ai models are becomes critical for implementation success.
Here’s how to think through the decision:
Start with function. What are you trying to accomplish? Prediction (classification or regression), discovery (clustering), creation (generation), or personalization (recommendation)? This narrows your options immediately.
Consider your data situation. Do you have labeled training data? If yes, supervised learning makes sense. If no, you’re looking at unsupervised or self-supervised approaches. Somewhere in between? Semi-supervised might be your path.
Evaluate interpretability requirements. Do stakeholders need to understand why the model made specific decisions? Decision trees and their ensembles offer transparency. Is maximum accuracy more important than explanation? Neural networks and gradient boosting deliver performance.
Match architecture to data type. Working with text? You need NLP models. Visual content? Computer vision. Structured tabular data? Ensemble methods typically win. Sequential decisions? Reinforcement learning makes sense.
Most real-world marketing AI systems combine multiple model types. Your email platform might use NLP models for subject line generation, classification models for send-time optimization, and recommendation systems for content selection, all working together.
The vendors who understand this will explain which model types they’re using and why. The ones who just say “we use AI” or “our proprietary algorithm” without specifics? Not worth your time.
We’ve spent years integrating AI-driven analytics and automation into marketing strategy, and the right model architecture dramatically impacts results. At The Marketing Agency, we don’t pick AI tools based on hype. We match model capabilities to specific business problems, whether that’s predictive lead scoring, content optimization, or campaign performance forecasting, implementing AI-driven systems through scalable campaign development that matches technical capabilities to business objectives.
I watched a team waste $50K last quarter on the wrong model type. They bought a neural network solution for a problem that needed simple decision trees. If you’re drowning in AI vendor pitches and can’t figure out which solve your problems, we can help you cut through the noise and build systems rooted in measurable performance rather than marketing trends.
Final Thoughts
Understanding different types of ai models isn’t about becoming a data scientist. It’s about asking better questions when vendors pitch you solutions, making smarter decisions about which tools to implement, and setting realistic expectations about what different AI approaches can deliver.
The four-category framework (learning architecture, functional capability, structural design, and application-specific specialization) gives you a lens for evaluating AI implementations. When someone pitches you an AI solution, you can now ask: How does it learn? What function does it perform? What’s the underlying architecture? Is it purpose-built for this domain?
Those questions reveal whether you’re dealing with a mature, well-designed system or just AI buzzword bingo.
The landscape shifts constantly. New architectures emerge, existing approaches get more capable, and what required custom development last year becomes a standard feature this year. But the core categories remain stable. You’ll always need to understand how models learn, what they do, how they process information, and whether they’re specialized for your use case.
Start with your business problem, not the technology. Figure out what you’re trying to accomplish, then work backward to identify which model types and learning approaches fit that objective. The marketers who win with AI are the ones who treat it as a tool for solving specific problems, not a magic solution for everything, understanding what is an ai model and applying that knowledge through AI implementation strategies that connect technical architecture to business value.
You now have the framework to make those decisions intelligently.