Companies are going to spend $634 billion on IT outsourcing by 2026, according to Statista. And most of them will be pissed about it.
Not because outsourcing doesn’t work. It does. But because they’re doing it wrong, and they’re doing it wrong in the exact same ways, every single time.
Time zones? Language barriers? “Cultural differences”? Those are excuses. The real problem is that most companies treat their outsourced teams like vending machines: insert requirements, receive code, complain when it doesn’t work. And then they’re shocked when the results are garbage.
Here’s what nobody wants to hear: when you treat skilled professionals as interchangeable order-takers instead of collaborative partners, you get exactly what you’ve designed for. Transactional work that meets specifications without solving problems.
You’re Outsourcing for the Wrong Reasons
Optimizing for Cost Creates a Race to the Bottom
Sure, 63% of companies cite cost reduction as their primary driver for outsourcing. Makes sense. But here’s what the CFO’s spreadsheet doesn’t show: the coordination overhead. The rework. The endless Slack threads explaining what should’ve been obvious. That 60% cost savings? It evaporates fast.
Hourly rate isn’t the real cost. The real cost is miscommunication. Misalignment. The constant context-switching needed to keep teams on track. That’s where your money goes.
When you optimize primarily for lower hourly rates, you’re implicitly devaluing the work itself. And guess what? You get exactly what you expected: mediocre results. We’ve seen this pattern repeat across industries. The “cheap” development option that seemed brilliant in the budget meeting becomes a nightmare six months later.
Look, budget constraints are real. Nobody’s saying spend money you don’t have. But there’s a difference between “we need specialized capability we don’t use full-time” and “we need cheaper labor.” One is strategy. The other is just cheap. And you get what you pay for.

I’ll call them ChartFlow (not their real name). Series B SaaS company, about 80 employees, building project management software. Their iOS app was a mess, and their two mobile developers had just left for Meta.
The CEO, David, found a Ukrainian dev shop on Clutch. $35/hour versus the $85/hour the experienced firms were quoting. The CFO loved the math: $200K savings on paper. The board loved it too. David had reservations but the numbers were hard to argue with.
Six months later, they had an app that technically worked but made no sense to actual users. One beta tester said it felt like “an Android app cosplaying as iOS.” Another: “Did the designers ever use a phone?”
The problem wasn’t the code quality. It was that nobody at ChartFlow had shared the three core workflows that 80% of users relied on. Or the Intercom tickets showing exactly where users got confused. Or the competitive analysis showing what users expected from mobile PM tools. Or why certain features were prioritized (spoiler: because their enterprise customers demanded them).
The dev shop wasn’t incompetent. They’d built exactly what was in the Jira tickets. But Jira tickets aren’t strategy.
Sarah, the product manager who’d been there since day one, was spending 15+ hours a week explaining context that should’ve been documented. She quit three months after launch. Couldn’t take it anymore.
The rework cost $347K. Not $350K. David remembers the exact number because the board asked about it three times. Four-month launch delay. NPS dropped 40 points.
The “cheap” option ended up costing more than the premium vendor would have, plus they lost Sarah, who was irreplaceable.
More Developers Doesn’t Equal More Output
Overwhelmed companies love to think: “We just need more hands.” So they outsource. More developers equals more output, right?
Wrong.
Onboarding takes time. Context-switching has a cost. Coordinating external team members creates overhead. You haven’t solved the bottleneck. You’ve just moved it. And possibly made it worse.
You can’t hire your way out of organizational chaos, whether those hires are employees or contractors.
Want to scale? Fix your processes first. Then add people.
Here’s what actually happens when you throw more developers at a broken process:
Slow feature delivery? New team members need months to become productive. Meanwhile, your internal team is spending 60% of their time onboarding, reviewing code from people who don’t understand the architecture, and answering questions that should’ve been documented. Fix your documentation and coding standards first.
Quality issues? More developers without clear quality gates means more bugs, not better code. Implement automated testing and define your code review process before you scale.
Missed deadlines? Additional team members require oversight from already-stretched internal staff. Fix your planning process and improve your estimation accuracy first.
Technical debt piling up? External teams optimize for immediate delivery, not long-term maintainability. Create architectural guidelines and make technical debt visible before you add capacity.
I watched a company try to solve their capacity problem by adding eight outsourced developers in one month. Their velocity dropped.
Not because the developers were bad. They were great. But the internal team was now spending most of their time onboarding, reviewing code from people who didn’t understand the system, and answering questions that should’ve been documented.
They’d traded one bottleneck (not enough developers) for another (not enough context). And the new bottleneck was worse because it was invisible on the roadmap.
What Happens When You Treat Teams Like Vendors
Transactional Relationships Get Transactional Work
When you keep outsourced teams at arm’s length, give them minimal context, and judge them only on whether they followed the spec, they optimize for exactly that. Meeting the letter of requirements without questioning whether those requirements make sense.
Then you complain that the work “lacks initiative” or “requires too much handholding.” But you’ve structured the relationship to produce exactly that behavior. You get what you incentivize, and transactional engagement structures incentivize checkbox completion, not problem-solving.
You know what’s wild? Companies spend months looking for outsourced teams who “think strategically” and “take ownership.” Then the second they hire them, they strip away every single thing that makes strategic thinking possible.
No context about the business. No access to users. No understanding of why this feature matters. Just a Jira ticket that says “build login screen” and an expectation that they’ll somehow intuit your entire product vision.
And then (and this is my favorite part) they complain that the team “lacks initiative.”

Keeping Teams in the Dark Is Expensive
When external teams don’t understand why they’re building something or how it fits into the bigger picture, they can’t make the tiny judgment calls that happen during execution. Should this error message be friendly or formal? Does this edge case matter? They’re guessing. And guessing leads to work that’s technically correct but completely misses the point.
Here’s what information asymmetry actually costs you:
20-30% of your project budget gets burned on rework. Features get rebuilt because they solved the wrong problem. Deadlines slip, which pushes back everything else on your roadmap. You finally ship something and it doesn’t move the metrics that matter.
Meanwhile, your product manager is working nights trying to keep everything aligned. Your internal team is frustrated because they’re constantly fixing things that should’ve been right the first time. And your external team is demoralized because they keep getting told their work isn’t good enough when the real problem is they were never given enough context to get it right.
This isn’t just expensive. It’s soul-crushing for everyone involved.
There’s a human cost too. When you keep external teams in the dark about broader business context, you’re signaling that they’re disposable. This affects retention and institutional knowledge on their end, which circles back to hurt you through constant turnover and knowledge loss.
Why “They Should Just Follow the Brief” Never Works
Even the most thorough documentation can’t anticipate every edge case, technical constraint, or shift that emerges during execution. Rigid adherence to initial specs, without room for intelligent adaptation, produces work that’s outdated by the time it’s delivered.
Treating briefs as contracts instead of starting points is a fundamental misunderstanding of how creative and technical work happens. Projects evolve. Requirements clarify. Priorities shift. The market moves. Expecting external teams to execute blindly against a document written three months ago is setting everyone up for failure.
The best outsourcing relationships we’ve seen treat specifications as shared understanding, not legal documents. They’re living artifacts that get refined through ongoing collaboration, not handed down from on high and enforced rigidly.
I learned this the expensive way. Early in my career, I wrote what I thought was a perfect spec document. Thirty pages, detailed mockups, acceptance criteria for every edge case. Handed it to our outsourced team in Poland and waited for magic.
What I got back was technically flawless and completely unusable. Because my “perfect” spec was written from my perspective, not the user’s. The team built exactly what I asked for, which turned out to be exactly the wrong thing. Cost us six weeks and a lot of humble pie.
Before you hand off any project, your external team needs to know:
Why this matters. Not “increase engagement by 15%.” The actual business bet you’re making. Are you trying to catch a competitor? Enter a new market? Fix a retention crisis? Be specific.
Who’s actually using this. Real users, not personas from a deck. Show them support tickets. Let them listen to user interviews. If you can’t do that, you don’t understand your users well enough to be building anything.
How this fits together. Your architecture, your APIs, the weird legacy system everyone works around. If your internal team knows about a gotcha, the external team needs to know too.
What good looks like. Show examples. Point to competitors. Share previous work you loved. “Good” is subjective. Make it concrete.
What they can decide versus what needs approval. Nothing kills momentum like waiting three days for permission to change a font size. Be explicit about boundaries.
Who to ask when they’re stuck. Not “the team.” Actual names of people who can answer domain questions.
What typically goes wrong. Common edge cases, error scenarios, places where users get confused. Don’t make them discover this the hard way.
What success actually means. Real metrics, not vanity metrics. How will you know if this worked?
What’s off the table. Constraints, non-negotiables, things that absolutely cannot change. Say it upfront.
This isn’t bureaucracy. This is the minimum context professionals need to do their jobs. Skip it and you’re guaranteeing mediocre results, regardless of talent.
What Makes Remote Collaboration Fail (It’s Not Time Zones)
Nobody Knows Who Can Decide What
I once watched a $2 million project grind to a halt because nobody could decide if the outsourced team was allowed to pick button colors. I’m not kidding. Button colors. The team would Slack the product manager, who’d check with the design lead, who’d want to loop in the VP, who was in meetings all day. Meanwhile, developers sat around waiting for permission to make a button blue.
Here’s a framework that actually works:
|
Decision Type |
Who Should Own It |
Required Documentation |
Escalation Trigger |
|---|---|---|---|
|
Technology stack choices |
Internal architecture team |
Architecture Decision Record with rationale |
When choice impacts multiple systems or has security implications |
|
UI/UX micro-interactions |
Outsourced design team |
Design system guidelines and component library |
When it conflicts with established patterns or accessibility standards |
|
Database schema changes |
Joint decision (internal + external leads) |
Schema documentation and migration plan |
Any breaking change or performance concern |
|
Bug fix approaches |
Outsourced development team |
Code review checklist and testing requirements |
When fix requires changing public APIs or affects other features |
|
Feature prioritization |
Internal product team |
Product roadmap and backlog with clear priorities |
Never. This stays internal |
|
Code refactoring decisions |
Outsourced development team |
Technical debt register and refactoring guidelines |
When refactoring will delay delivery by more than 20% |
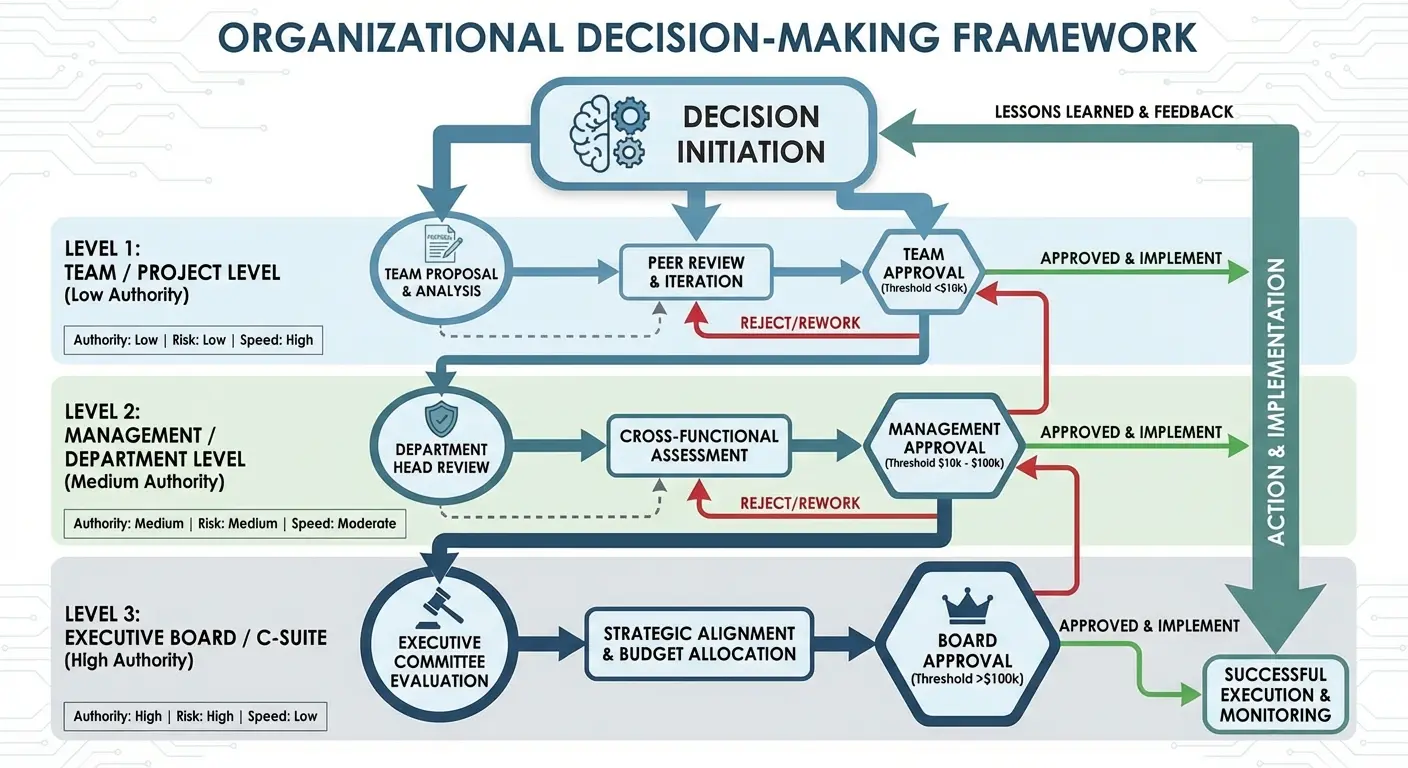
We’ve seen outsourcing relationships transform overnight when companies finally document decision boundaries. Suddenly, the “slow” external team starts moving faster because they’re not waiting for permission to make routine choices. The “unresponsive” internal team stops being a bottleneck because they’re only involved in decisions that truly require their input.
Communication Protocols Default to Chaos Without Explicit Design
The absence of clear communication structures creates more friction than any time zone difference ever could. When some updates go in Slack, others in email, some in Teams, critical decisions happen in Zoom calls that nobody records, and your “source of truth” is a Notion doc that hasn’t been updated since March, you’ve built a system that guarantees miscommunication.
Assuming “everyone will figure out how to stay aligned” is backwards when working with distributed teams. Different types of information need different channels. Different stakeholders need different loops. Decisions need to be documented and communicated consistently.
You have to actually plan this stuff.
The companies succeeding with outsourcing have explicit protocols around information flow, and they enforce those protocols religiously.
Async Work Requires Different Skills
Writing clearly becomes more critical than speaking articulately. Documenting context becomes more important than being charismatic in meetings. Anticipating questions and providing comprehensive information upfront becomes essential rather than optional.
Many companies outsource to remote teams without recognizing that their internal team lacks these async-first skills, then blame the outsourced developers when communication breaks down. Successful remote collaboration requires deliberate skill development on both sides.
GlobalTech (fake name) had teams in San Francisco, Krakow, and Bangalore. They were building a data analytics platform, and nothing was getting done.
The problem wasn’t time zones. They’d figured out async work. The problem was that decisions made in SF meetings weren’t being written down. The Krakow team would implement something based on their understanding, the Bangalore team would build a conflicting approach, and SF would discover the misalignment three weeks later during a demo.
Their VP of Engineering, Marcus, finally lost it during a sprint review when he saw two completely different authentication systems being presented. “Did nobody talk to each other?” he asked.
They had talked. They’d had meetings. But nobody had documented what was decided, so each team filled in the gaps with their own assumptions.
The fix wasn’t complicated. They created a “communication charter” that sounds bureaucratic but was actually simple: write down decisions, use templates, make nothing official until it’s documented.
Most importantly, they established that any decision made synchronously (in a meeting) wasn’t official until documented asynchronously. Within two months, their rework rate dropped 40% and their offshore team reported feeling significantly more empowered to make decisions, because they could reference documented precedents rather than guessing at context they’d missed in meetings held during their night.

The shift from synchronous to asynchronous-first communication isn’t just about accommodating time zones. It’s about creating a written record that becomes institutional knowledge, accessible to anyone who needs it, whenever they need it. This benefits everyone, including your internal team.
Building Continuity When People Keep Leaving
Turnover Hits Harder When Nothing’s Written Down
Outsourcing partners experience turnover, sometimes higher than you’d see internally, and you have limited control over it. When the developer who understood your codebase quirks or the designer who knew your brand instinctively leaves, you’re starting over unless you’ve built systems to capture and transfer that knowledge.
Many companies only discover how dependent they were on specific individuals after those individuals are gone. By then, it’s too late. The knowledge walked out the door, and you’re left with code nobody understands or design files nobody can interpret.
The challenge of maintaining continuity amid turnover is becoming even more critical as AI reshapes team structures. According to a recent profile of Boca Raton-based outsourcing platform Scoutt, the traditional “bench” model (where firms rotate available developers onto client projects) is giving way to more deliberate matching based on skills, culture fit, and project requirements.
As Scoutt’s CTO Moran Alkobi notes, “The future of software outsour cing isn’t about finding more developers, it’s about intelligently combining human expertise with AI capability.” This shift means that when a team member leaves, you’re not just losing their coding knowledge. You’re losing their understanding of how to orchestrate AI tools within your specific context, making knowledge transfer even more critical than before.
Organizations implementing application modernization strategies understand that knowledge continuity becomes even more critical when legacy systems are being transformed. You can’t afford to lose the people who understand both the old system and the new one.
Onboarding Never Stops
Treating onboarding as something that happens once, at the beginning of an engagement, sets up inevitable knowledge degradation over time. As your product evolves, your processes change, and your priorities shift, outsourced teams need continuous re-onboarding to stay aligned.
Building evergreen onboarding resources that get updated as your company changes is essential. So are regular touchpoints specifically designed to refresh context and realign understanding. Onboarding is a living system, not a checklist you complete and forget.

We’ve worked with partners who maintain “onboarding sprints” every quarter, where they review and update all context documentation, refresh team members on priorities, and explicitly discuss what’s changed since the last review. This practice catches drift before it becomes misalignment.
The Rotation Problem
Outsourcing companies rotate team members frequently, either by design (to provide “fresh perspectives”) or by necessity (due to their own capacity constraints). When this happens without careful management, you’re constantly working with people who lack deep context, which increases oversight burden and reduces work quality.
Software outsourcing companies love to talk about “fresh perspectives” when they rotate team members. Fresh perspectives. Like your codebase is a creative writing workshop that benefits from new eyes every quarter. What you actually get is fresh confusion and a developer who doesn’t know why that weird workaround exists in the payment flow.
What is outsourcing if not access to expertise? But expertise without context is just theoretical knowledge. The developer who knows React inside and out still needs three months to understand your specific architecture, your data models, your user workflows, and your technical debt landscape.
Negotiating team stability upfront is ideal. When that’s not possible, you need documentation and knowledge systems so robust that rotation becomes less disruptive. This is hard work. It’s also the only alternative to perpetual beginner syndrome.
Here’s what rotation actually looks like on the ground:
You spend six weeks getting a developer up to speed on your system. They finally understand the architecture, the business logic, the weird edge cases. They’re productive. They’re making good decisions.
Then they rotate off. New developer comes in. You’re back to square one.
Except it’s worse than square one, because now you’ve got code written by someone who’s gone, and the new person doesn’t understand why it was built that way. So they either avoid touching it (technical debt accumulates) or they refactor it without understanding the constraints (things break).
You’re not building software anymore. You’re running an onboarding factory.
Look, I’m about to give you a transition template that’s going to feel like a lot. Most companies won’t do it. They’ll say “we don’t have time for this overhead.”
Those companies will then spend three months getting a new team member up to speed, during which they’ll lose critical knowledge, make preventable mistakes, and wonder why outsourcing is “so hard.”
Your choice. Here’s what actually works:
When someone leaves: They record a video walkthrough. Fifteen minutes, screen share, talking through their main areas. Not documentation, just a brain dump. “Here’s where the weird stuff is, here’s what trips people up, here’s what I’d do differently.”
They write down the tribal knowledge. The stuff that’s not in the wiki because it seemed too obvious or too small. The workarounds. The gotchas. The “don’t touch this code because it breaks the reporting system.”
They list everything in progress with actual status. Not “mostly done.” What’s actually finished, what’s blocked, what’s next.
When someone new comes in: They don’t touch code for a week. They read, they watch videos, they pair with someone. I know this feels slow. It’s faster than letting them break things while learning.
They have a buddy. Not a manager. A peer who’s been around and can answer the “why is this so weird” questions.
Their velocity is cut by 30% for the first sprint. Plan for it. Don’t pretend they’ll be full speed on day one.
And the manager’s job is to identify what knowledge is at risk and make sure it gets captured before it walks out the door.
Will this prevent all knowledge loss? No. Will it prevent most of it? Yes. Is it worth the overhead? Only if you care about not starting from scratch every time someone rotates off your project.
The Documentation Problem Nobody Wants to Admit
Your Internal Team Doesn’t Document Well Either
Let’s be honest: your internal documentation is probably terrible.
You’ve got critical business logic living in someone’s head, architectural decisions that were made in a Slack thread two years ago, and a README that was last updated in 2019. Your own employees navigate this by asking the guy who’s been there forever.
Now you’re mad that your outsourced team can’t figure it out? Come on.
Most companies have terrible documentation practices internally, then expect outsourced teams to navigate undocumented systems and processes. Outsourcing often exposes pre-existing documentation debt that was previously masked by hallway conversations and institutional knowledge. The developer who could answer any question about the legacy payment system just quit? Suddenly you realize nobody else knows how it works, and there’s no documentation to consult.
Improving documentation to support outsourced teams improves internal operations as well. New employees onboard faster. Cross-functional collaboration becomes smoother. Knowledge doesn’t evaporate when people take vacation or leave the company.

We’ve never seen an external team struggle with clients who have excellent documentation. The correlation is nearly perfect. Organizations that document well succeed with external teams. Organizations that don’t, struggle.
Documentation Isn’t Just Writing Stuff Down
Having information somewhere isn’t enough. People need to be able to find it when they need it, understand it without extensive explanation, and trust that it’s current.
Good documentation requires infrastructure: clear organization, consistent formatting, regular maintenance, version control, and search functionality. Many documentation efforts fail not because people don’t write things down, but because what gets written is scattered, outdated, or incomprehensible without insider knowledge.
You know that Confluence page titled “System Architecture – DRAFT” that’s been a draft for eighteen months? Or the README that says “TODO: Add setup instructions”? That’s what I’m talking about.
The documentation landscape is being transformed by AI-powered tools that are changing what “good documentation” even means. According to a16z’s analysis of the AI software development stack, modern development workflows now include “documentation for developers and LLMs” as a distinct category.
Tools like Context7 and Mintlify can “automatically pull in the right context at the right time, retrieving relevant code, comments, and examples, so the generated documentation stays consistent with the actual implementation.” This shift means documentation is no longer just for human readers. It’s becoming infrastructure that both people and AI agents rely on to understand and extend your systems.
Companies that treat documentation as an afterthought aren’t just hampering their external teams. They’re limiting their ability to leverage AI acceleration across their entire development lifecycle. Your outsourcing partner can only be as effective as the documentation you provide them.
Teams working on digital transformation initiatives discover quickly that documentation becomes the foundation for successful technology adoption across distributed teams. You can’t transform what you can’t explain.
When Tribal Knowledge Hurts You
Relying on tribal knowledge (information that lives only in people’s heads and spreads through informal conversations) creates fragility in your organization. It’s not just an outsourcing problem. It’s a scaling problem, a succession problem, and a risk management problem.
Companies that successfully work with outsourced teams are often forced to formalize knowledge that should have been documented all along. This formalization makes them more resilient and scalable overall. What is outsourcing if not a forcing function for organizational maturity?
Here’s the kicker: companies resist documentation because it’s “too much overhead,” then spend exponentially more time answering the same questions repeatedly, onboarding new team members from scratch, and recovering from knowledge loss when people leave.
I know what you’re thinking: “We don’t have time to document everything.”
Neither does anyone else. But you know what takes more time? Explaining the same thing to five different people across three time zones. Redoing work because the context was in someone’s head. Onboarding a replacement when that person quits.
You don’t need perfect documentation. You need enough documentation that people can be productive without constant interruption. That’s a lower bar than you think.
Side note: I once consulted for a company that had hired a technical writer specifically to improve their documentation. Six months in, the writer quit because (and I’m quoting the exit interview) “nobody actually wants documentation, they just want to complain about not having it.”
She wasn’t wrong. The engineering team would complain about lack of docs, then skip every documentation review she scheduled. They wanted documentation to exist magically without them having to participate in creating it.
Anyway.
Stop Measuring Output. Measure Integration.
Counting Deliverables Tells You Nothing
Evaluating outsourced teams primarily on how many things they produce optimizes for quantity over quality. This metric encourages work that’s technically complete but strategically misaligned, and creates perverse incentives to avoid the collaborative friction that improves outcomes.
The fixation on deliverable velocity rather than integration quality is a primary driver of failure. Research shows that 20-25% of all outsourcing relationships fail within the first two years, but the root cause isn’t technical incompetence. It’s operational misalignment.
Most tellingly, 55% of organizations begin outsourcing engagements without defined success metrics, which means they’re measuring activity (features shipped, tickets closed, hours logged) rather than outcomes (user satisfaction, system stability, business impact). When you don’t define what success looks like beyond “they delivered what we asked for,” you end up with a pile of technically correct work that doesn’t solve the problem.
How well does outsourced work integrate with your broader goals? How much rework does it require? How does it perform against business objectives rather than just completion criteria? These metrics are harder to track, but they’re infinitely more meaningful.
The Rework Spiral: When “Done” Doesn’t Mean “Right”
Work that meets specifications but still requires significant revision because it doesn’t solve the underlying problem is expensive. This pattern happens due to lack of context, transactional relationships, and poor communication. All the issues we’ve discussed.
Are you constantly sending work back for revision? Do completed features require extensive modification before they’re usable? Are you spending more time managing the outsourced team than you would have spent doing the work internally?
These are signs that something in your engagement structure is broken. Multiple revision rounds aren’t evidence that the outsourced team is incompetent. They’re evidence that you haven’t set them up for success.
A financial services company outsourced the development of a customer portal to a highly credentialed offshore team. The team delivered every sprint on time, hit every acceptance criterion, and maintained pristine code quality metrics.
Yet three months after launch, the portal had a 60% abandonment rate and generated twice the support tickets as the legacy system it replaced. The problem wasn’t the code. It was that the outsourced team had optimized for meeting documented requirements without understanding the user workflows.
They’d built exactly what was specified: a secure, compliant system that technically worked. But because they’d never been given access to customer research, support ticket histories, or the reasoning behind legacy design decisions, they couldn’t make the intelligent micro-decisions that turn specifications into great user experiences.
The company spent another six months and roughly $400,000 rebuilding core flows, work that could have been avoided if they’d invested in proper context transfer upfront. The “efficient” approach of keeping the outsourced team focused narrowly on specs ended up being the most expensive option possible.
The PM who managed that project quit three months after launch. Not because she was bad at her job. Because watching hundreds of thousands of dollars get lit on fire while everyone blamed “the offshore team” was soul-crushing. She saw the real problem: leadership had set everyone up to fail. But admitting that would’ve required accountability nobody wanted.
Catch Problems Early
Building review and feedback processes that catch misalignment early, when it’s still cheap to fix, requires thinking beyond bureaucratic checkboxes. Quality gates should genuinely improve outcomes, not just create approval bottlenecks.
Structuring reviews so they’re collaborative rather than adversarial changes everything. The goal isn’t to catch the outsourced team making mistakes. It’s to ensure everyone’s aligned on what “good” looks like before significant work happens.
Giving feedback that helps teams get better over time rather than just fixing immediate problems is an investment that pays dividends. Each cycle should reduce the need for oversight, not maintain it at the same level indefinitely.
When Hiring In-House Is Actually Worse
The Full-Time Employee Fallacy
The assumption that hiring internally is always better than outsourcing isn’t as obvious as it seems. The permanence of full-time employees can create complacency. Internal politics can interfere with work quality. The sunk cost of salaries and benefits can keep underperforming team members in place longer than they should be.
Full-time employees get comfortable. They know you’re not going to fire them over one bad quarter, so performance drifts. Meanwhile, that underperforming developer you hired eighteen months ago? Still on the team because firing is hard and HR is involved and it’s just easier to route work around them. At least with outsourcing, you can end the contract.
We’re not arguing against internal hiring. We’re pushing back on the reflexive belief that it’s inherently superior. The right choice depends on the type of work, your organizational maturity, and your capacity to manage and develop talent.
Outsourcing done well can deliver better results than mediocre internal hiring done poorly. The inverse is also true. The employment relationship matters less than the quality of the relationship and the fit between the work and the team structure.
Here’s something nobody wants to hear: sometimes your internal team is worse than the outsourced team.
They’re slower. They’re more expensive. They’re more resistant to change. And you can’t fire them without a nine-month HR process.
That “expensive” outsourced team that questions your assumptions? Sometimes they’re seeing things your internal team is too close to see. Sometimes they’re right and you’re wrong.
I’ve watched companies waste years defending bad internal decisions because admitting the outsourced team was right would’ve required someone senior to admit they were wrong. Pride is expensive.
Don’t Hire Full-Time for Part-Time Needs
Hiring a full-time employee for skills you use 20% of the time means either paying for unused capacity or forcing that person into work they’re not suited for. Neither option makes sense.
Identifying which capabilities genuinely need to be in-house versus which are better accessed through external partnerships is a strategic decision, not just a financial one. Capabilities that are business-critical, require deep institutional knowledge, or you use constantly should probably be internal. Everything else is negotiable.
Outsourcing for specialized, periodic needs is often smarter than hiring. You get access to expertise when you need it, without the overhead of maintaining it full-time. What is outsourcing if not strategic access to capabilities you need but don’t need to own?
|
Work Characteristic |
Keep In-House |
Consider Outsourcing |
|---|---|---|
|
Frequency of need |
Daily or weekly usage |
Periodic or project-based need |
|
Strategic importance |
Core differentiator for your business |
Necessary but not differentiating |
|
Knowledge requirements |
Deep institutional context required |
Mostly technical/domain expertise |
|
Decision velocity |
Requires real-time, high-stakes decisions |
Can tolerate some decision latency |
|
Integration complexity |
Tightly coupled with multiple systems |
Loosely coupled or well-defined interfaces |
|
Skill availability |
Abundant in your local market |
Scarce or expensive locally |
|
Longevity |
Ongoing maintenance and evolution |
Defined endpoint or stable state |
|
Regulatory exposure |
High compliance or security risk |
Standard security practices sufficient |

This framework helps you think systematically about where to draw the line between internal and external resources. There’s no universal right answer, but there are principles that guide better decisions.
The Flexibility Premium Is Worth It
Being able to scale capacity up and down based on need has value. While outsourcing often costs more per hour than an equivalent internal salary, it provides flexibility that can be worth the premium.
This flexibility matters most when you’re dealing with seasonal businesses, project-based work, experimental initiatives where you’re not sure of ongoing need, and growth phases where you need to move fast without long-term commitments.
Working with a partner that can flex capacity means you’re not stuck with excess headcount when projects wind down or market conditions shift. You’re also not scrambling to hire when opportunities emerge suddenly.
Thinking through when flexibility is worth paying for versus when stability justifies the commitment of full-time headcount is part of mature resource planning. Both models have their place. The mistake is treating one as universally superior to the other.
What You Need to Remember
Your outsourcing problems aren’t outsourcing problems.
They’re communication problems. Documentation problems. Decision-making problems. Problems you probably have internally too, but they’re masked by hallway conversations and the ability to tap someone on the shoulder.
Outsourcing just makes them visible. And expensive.
The companies that succeed with external teams aren’t the ones with the biggest budgets or access to the best developers. They’re the ones that have their shit together internally first.
Clear communication protocols. Explicit decision rights. Documentation that doesn’t suck. Outcome-based measurement instead of activity tracking.
Build that foundation and any competent external team will succeed. Skip it and even the most talented developers will struggle.
I’ve seen this play out dozens of times. The company that blames “the offshore team” for poor results is always (always) the company with unclear requirements, undocumented systems, and no process for making decisions.
The good news? You control all of that. You don’t need to find the perfect vendor who magically compensates for your organizational dysfunction. You need to fix the dysfunction.
Do that and outsourcing stops being a gamble. It becomes what it should be: strategic access to expertise you need but don’t need to employ full-time.
The future of work is distributed whether you like it or not. Companies that figure out how to integrate external expertise effectively won’t just have better outsourcing relationships. They’ll be able to move faster, scale smarter, and adapt quicker than competitors who insist on doing everything in-house.
Your call.