Everyone’s building the wrong neural networks. Not because the architectures are bad (they’re great at what they do) but because we’ve forgotten why we chose them in the first place.
We’ve optimized neural network architectures for performance metrics while sacrificing interpretability, creating models we can’t fully explain or trust. Abandoned architectures from the past decade contain valuable lessons about trade-offs we’ve forgotten to consider. The push toward standardization (transformers for everything) limits our ability to match architecture to problem type. Your architecture choice reveals more about your constraints and assumptions than your actual problem.
The Architecture Graveyard: What Discarded Designs Teach Us
You don’t learn much from success stories in neural network design. The architectures that dominate today (transformers, ResNets, U-Nets) tell you what worked, but they don’t tell you what you sacrificed to get there. According to research published by V7 Labs, countless new neural network architectures are proposed and updated every single day, yet the evolution from simple artificial neural networks to architectures consisting of millions of parameters trained on tons of data reveals a narrowing focus on scalability over other critical design considerations.
Capsule networks promised better spatial reasoning and part-whole relationships. Geoffrey Hinton himself championed them as a solution to the fundamental limitations of CNNs. They made intuitive sense: instead of scalar activations, use vectors that encode both the presence and properties of features.
We abandoned them because they were computationally expensive and didn’t immediately outperform existing solutions on benchmark datasets.
That decision reveals something critical about our field’s priorities. We chose speed and benchmark performance over architectural elegance and theoretical soundness. I’m not saying capsule networks were the answer, but the reason we stopped exploring them matters. We decided that incremental improvements on ImageNet mattered more than solving the underlying conceptual problems with convolutional approaches.
Neural Turing machines faced a similar fate. The idea was compelling: give networks external memory they could read from and write to, creating something closer to algorithmic reasoning. Early results showed promise for tasks requiring multi-step logic. But they were hard to train, required careful initialization, and didn’t scale well.
The research community moved on.
This pattern bothers me. We keep encountering the same limitations (poor generalization, inability to reason, catastrophic forgetting, which is a fancy way of saying the model forgets everything it learned before). Yet we’ve stopped exploring the architectural ideas that specifically targeted those problems. Instead, we throw more parameters and more data at transformer variants and hope emergence solves everything.
The neural network architectures we discard tell a story about what we value. Speed over elegance. Benchmark scores over conceptual soundness. Immediate results over long-term solutions to fundamental problems.
Why Efficiency Became the Wrong North Star
Efficiency isn’t inherently bad. The problem is we’ve defined it too narrowly.
When researchers say an architecture is “efficient,” they typically mean it achieves competitive accuracy with fewer parameters or faster training times. That’s one valid definition, but it ignores efficiency along other dimensions that matter just as much in practice: sample efficiency (how much training data you need), energy efficiency (total computational cost including deployment), debugging efficiency (how quickly you can identify and fix problems), and adaptation efficiency (how easily you can modify it for new tasks).
We optimized almost exclusively for parameter efficiency and training speed because those were easy to measure and compare.
The result? Architectures that look great in papers but create nightmares in production. Understanding the different types of neural network architectures and their efficiency trade-offs becomes critical when moving beyond academic benchmarks.
|
Efficiency Dimension |
Traditional Definition |
Practical Reality |
Why It Matters |
|---|---|---|---|
|
Parameter Efficiency |
Fewer weights to achieve same accuracy |
May sacrifice interpretability and modularity |
Benchmark favorite, but not always production-ready |
|
Sample Efficiency |
Data required to reach target performance |
Often ignored in favor of “data is cheap” mindset |
Critical for specialized domains with limited labeled data |
|
Energy Efficiency |
Total computational cost (training + inference) |
Rarely measured beyond FLOPs |
Determines deployment feasibility and environmental impact |
|
Debugging Efficiency |
Time to identify and fix model failures |
Never appears in papers |
Dominates real-world development cycles |
|
Adaptation Efficiency |
Effort to modify for new tasks or domains |
Assumed via transfer learning |
Determines long-term maintainability |

Transformers are the perfect example. They’re incredibly parameter-efficient for language tasks and parallelize beautifully during training. But they’re sample-inefficient (requiring massive datasets), energy-intensive (both in training and inference), and nearly impossible to interpret or debug when they fail.
For many real-world applications, that trade-off doesn’t make sense.
You see this pattern everywhere. EfficientNets optimized for FLOPs and parameter count, but they introduced complex scaling rules that made them harder to adapt and understand. MobileNets prioritized inference speed on mobile devices, which sounds practical until you realize the accuracy degradation makes them unsuitable for many applications where mobile deployment would otherwise be valuable.
Interpretability used to be a design consideration. Early neural networks were small enough that you could, in principle, trace the activation path for a given input and understand the computation.
We gave that up gradually, then suddenly.
The shift happened when we decided that matching human performance on specific tasks mattered more than understanding how the system worked. That might be acceptable for some applications (who cares how a spam filter works as long as it’s accurate?) but we’ve applied the same logic to medical diagnosis, loan decisions, and content moderation. When someone asks “what is a neural network doing with this data?” we should have clear answers, but the architecture choices we made for ImageNet classification are now embedded in systems making consequential decisions about people’s lives.
A hospital deployed a deep learning model for pneumonia detection from chest X-rays. The model achieved 94% accuracy on the test set. Impressive by any measure. But when radiologists reviewed flagged cases, they discovered the model was partly relying on the presence of medical equipment in images (ventilators, ECG leads) rather than actual pathological features. Patients with severe pneumonia are more likely to be in intensive care with equipment visible in their X-rays. The model learned a correlation, not causation.
Because the architecture was optimized purely for accuracy without interpretability constraints, this dangerous shortcut went undetected until deployment. An architecture designed with interpretability as a first-class constraint (perhaps with attention mechanisms that radiologists could review, or concept bottleneck layers that explicitly identified anatomical features) would have revealed this flaw during development.
There’s a middle ground where we could design architectures with interpretability as a first-class constraint, not an afterthought.
Robustness to distribution shift is another casualty. We test models on held-out data from the same distribution as the training set, declare victory, and deploy them into environments where that assumption breaks down immediately. Architectures that might be slightly less accurate but more robust to domain shift get dismissed because our evaluation protocols don’t value that property.
The same goes for uncertainty quantification. Most modern neural network architectures output confident predictions even when they’re wildly uncertain. We could design architectures that explicitly model uncertainty (Bayesian neural networks tried this), but they’re more complex and don’t improve benchmark scores, so they remain niche.
The Forgotten Trade-Off Between Interpretability and Performance
Nobody explicitly decided to abandon interpretability. It happened through a thousand small choices that each seemed reasonable in isolation.
Deeper networks outperformed shallow ones, so we went deeper. End-to-end learning eliminated the need for hand-crafted features, so we let the model learn everything. Attention mechanisms improved performance, so we stacked them without fully understanding why they worked.
Each step made individual sense, but the cumulative effect was architectures that operate as black boxes.
AlexNet (2012) was deep but still somewhat interpretable. You could visualize the filters and see that early layers learned edge detectors and later layers learned more complex patterns. By the time we reached ResNet-152 (2015), interpretation became effectively impossible. The skip connections that made training feasible also made it much harder to understand what any individual layer contributed. When people ask “what is a neural network really doing?” at this level of complexity, we struggle to provide satisfying answers beyond pointing to artificial neural networks’ overall performance metrics.
Transformers took this further. The attention mechanism seems interpretable at first (you can visualize attention weights), but those visualizations are often misleading. Attention weights don’t necessarily indicate what the model is “looking at” in any meaningful sense. Multiple attention heads interact in complex ways, and the residual connections mean information flows through the network along paths you can’t easily trace.
Was this trade-off necessary? Or did we just stop trying to build interpretable architectures because it was harder and didn’t improve benchmark scores?
Neural module networks (NMNs) represented a genuine attempt to build interpretability into the architecture itself. The idea was to compose task-specific modules into different configurations based on the input. For visual question answering, the model would dynamically assemble a pipeline: maybe a “find” module, then a “relate” module, then a “count” module. You could trace the execution path and understand the reasoning process.
They worked, but not well enough to compete with end-to-end approaches that learned everything jointly. The modular structure imposed constraints that limited performance.
The field moved on.
Concept bottleneck models took a different approach: force the network to make predictions through a layer of human-interpretable concepts. For medical diagnosis, the model might first predict the presence of specific symptoms or visual features, then use those predictions to reach a diagnosis. You sacrifice some accuracy (the bottleneck constrains information flow), but you gain interpretability and the ability to intervene when the model gets concepts wrong.
I talked to someone at a financial services company building a loan approval system. They faced regulatory requirements to explain every rejection. Their initial transformer-based model achieved 89% accuracy but produced explanations that were essentially post-hoc rationalizations. The model made decisions through its black-box layers, then a separate explanation module tried to justify them.
They redesigned using a concept bottleneck architecture. The model first predicted interpretable financial health indicators (debt-to-income ratio category, payment history score, employment stability index), then made the final approval decision based on those concepts. Accuracy dropped to 86%, but now every decision could be traced through specific, auditable concepts. When the model rejected an application, loan officers could see exactly which financial health indicators triggered the rejection and discuss them meaningfully with applicants. The 3% accuracy sacrifice bought them regulatory compliance, customer trust, and the ability to identify and correct biased patterns in the concept layer.
These neural network architectures didn’t fail because they were bad ideas. They failed because we weren’t willing to accept even small performance degradations in exchange for interpretability. The research incentives pointed toward state-of-the-art benchmark results, not toward building systems that humans could understand and trust.
When Biological Inspiration Stopped Being Useful
Neural networks started as explicit models of biological neurons. The perceptron was Frank Rosenblatt’s attempt to build a machine that learned the way brains do. Early convolutional networks were directly inspired by Hubel and Wiesel’s discoveries about the visual cortex: simple cells that detect edges, complex cells that pool over spatial positions, hierarchical processing.
That biological inspiration was useful early on. It gave us architectural principles: hierarchical processing, local connectivity, weight sharing.
But at some point, the connection to neuroscience became more metaphorical than practical.
Backpropagation doesn’t happen in brains (at least not in the way we implement it). ReLU activations are convenient for optimization but have little biological justification. Batch normalization, dropout, attention mechanisms… none of these have clear biological correlates. We kept the “neural” terminology while building systems that work nothing like biological brains. Understanding what is neural network computation in biological terms versus artificial terms reveals this fundamental divergence.
That’s not necessarily a problem. Airplanes don’t flap their wings, and that’s fine.
But we’ve lost something by completely abandoning biological plausibility as a design consideration. Brains are incredibly sample-efficient, energy-efficient, and robust to noise and damage. They handle continual learning without catastrophic forgetting. They generalize compositionally and reason abstractly.
Recent research is attempting to bridge this gap. According to a comprehensive survey from Quantum Zeitgeist, scientists at The University of Arizona are advancing Spiking Neural Network architecture search (SNNaS), examining how biologically-inspired networks that use discrete spikes instead of continuous activations could offer dramatically improved power efficiency and real-time processing. The research highlights that traditional gradient-based optimization methods are ineffective for SNNs due to the discrete nature of spike functions, requiring specialized performance metrics beyond standard accuracy (including spike timing precision, firing rates, and temporal dynamics).
Some researchers are trying to bring biological inspiration back. Spiking neural networks use discrete spikes instead of continuous activations, more closely mimicking biological neurons. They’re potentially much more energy-efficient, but they’re harder to train and haven’t achieved competitive performance on standard benchmarks. Predictive coding networks implement a biologically-plausible learning algorithm based on prediction errors. They show promise for unsupervised learning and handling temporal structure.
These approaches remain niche because they don’t immediately outperform existing methods.
Maybe we’re optimizing for the wrong things again.
Brains learn new concepts from single examples. Show a child one picture of a giraffe, and they’ll recognize giraffes forever. Our best models need thousands of examples, sometimes millions. That’s not a data problem or a scale problem. It’s an architectural one. When you examine what is a neural system’s learning mechanism in biological organisms, this efficiency gap becomes glaring.
The difference isn’t just efficiency. Humans compose concepts hierarchically and reuse them flexibly. We learn “tall,” “spotted,” and “long neck” as separate concepts, then combine them. Our architectures learn entangled representations that can’t be decomposed or recombined easily. Few-shot learning methods try to patch this limitation, but they’re working against the architecture rather than with it.
Continual learning is another fundamental gap. You can’t train a neural network on task A, then task B, without it forgetting task A. We call this catastrophic forgetting, which is a polite way of saying our architectures have no memory consolidation mechanism. Brains somehow integrate new information without overwriting old knowledge. We’ve tried various solutions (elastic weight consolidation, progressive neural networks, replay buffers), but they’re all workarounds for an architectural limitation.
Temporal credit assignment over long horizons remains unsolved. Brains can connect actions to outcomes separated by hours
Temporal credit assignment over long horizons remains unsolved. Brains can connect actions to outcomes separated by hours or days. Our reinforcement learning architectures struggle with delays beyond a few hundred steps, even with tricks like hindsight experience replay.
That’s not a learning algorithm problem. It’s about how we structure information flow through time.
The scale of this challenge becomes clear when examining current architectures. Research from V7 Labs indicates that very deep neural networks are extremely difficult to train due to vanishing and exploding gradient problems, limitations that biological systems seem to avoid entirely through fundamentally different architectural principles around memory consolidation and information persistence.
The Hidden Cost of Standardization
Walk into any machine learning team, and you’ll find them using the same architectures as everyone else. Vision problems? ResNet or Vision Transformer. Language? Some transformer variant. Segmentation? U-Net. Recommendation? Two-tower architecture or transformer again.
This standardization didn’t happen because we proved these neural network architectures are optimal. It happened because they’re good enough, well-documented, and have pretrained weights available. The path of least resistance is to grab a pretrained model and fine-tune it.
That’s rational behavior at the individual level. Why spend months designing and testing a custom architecture when you can download BERT or ResNet-50 and get decent results in days? But at the field level, we ‘ve created a monoculture that stifles architectural innovation.
The problem compounds itself. New researchers learn these standard architectures, so they become the baseline for all future work. Papers that propose new neural network architectures have to beat the established ones on standard benchmarks, which is difficult because those benchmarks were often designed around the capabilities of existing architectures. Funding and publication incentives favor incremental improvements to proven approaches over risky exploration of new designs.
Pretrained models make this worse. The massive computational cost of training foundation models means only a few organizations can afford it. Everyone else fine-tunes their models, which means we’re all building on the same architectural foundations.
If those foundations have fundamental limitations, we’re all stuck with them.
Neural ODEs treat neural networks as continuous dynamical systems rather than discrete layers. They’re elegant theoretically and offer benefits like adaptive computation (spend more time on hard examples) and memory efficiency (you don’t need to store activations for every layer). They haven’t caught on because they’re slower to train and don’t have pretrained models you can download.

That’s a chicken-and-egg problem. Nobody trains large-scale neural ODE models because there’s no infrastructure for it. There’s no infrastructure because nobody uses them. Meanwhile, we keep investing in transformer infrastructure, making transformers even more dominant.
Architectures with explicit external memory face similar challenges. Differentiable neural computers and memory networks showed promise for tasks requiring complex reasoning and information retrieval. They could potentially handle longer contexts more efficiently than transformers’ quadratic attention. But they’re harder to implement, harder to optimize, and don’t have the ecosystem support that transformers enjoy.
Hybrid symbolic-neural architectures combine neural perception with symbolic reasoning. They could potentially offer better compositional generalization and interpretability than pure neural approaches. But they require expertise in both neural networks and symbolic AI, which few researchers have. They also don’t fit neatly into existing training pipelines and frameworks.
While modern neural network architectures dominate research and deployment, these alternative directions languish without the infrastructure support needed to prove their potential.
Architectures That Failed Forward
Memory networks were supposed to solve the context problem. Instead of cramming everything into fixed-size hidden states, give the network explicit external memory it could read and write. Early results on question-answering tasks were promising. The architecture made intuitive sense.
They didn’t scale. The attention mechanism over memory became a bottleneck as memory size grew. Training was unstable. The discrete read/write operations were hard to optimize. Transformers came along and solved the same problems more elegantly (or at least more practically), and memory networks faded away.
But we never really figured out why they didn’t scale. Was it a fundamental architectural limitation, or did we just not try hard enough? Transformers had their own scaling challenges early on (training instability, memory requirements), but we invested heavily in solving those problems because the architecture seemed promising.
We didn’t give memory networks the same chance.
Highway networks and residual connections tell a different story. Highway networks (2015) introduced gating mechanisms to help gradients flow through deep networks. They worked but were complex. Residual connections (2015) achieved similar benefits with a simpler mechanism: just add the input to the output.
ResNets won because simplicity scales better than complexity.
That’s a genuine lesson about architecture design: elegant simplicity beats clever complexity when you’re trying to scale. But we’ve over-learned that lesson. Now we dismiss architectures that seem complex without investigating whether that complexity is necessary or whether it could be simplified. The evolution of artificial neural networks has taught us that sometimes complexity serves a purpose we don’t immediately recognize.
Boltzmann machines were theoretically beautiful. They had a principled probabilistic interpretation, could learn complex distributions, and had connections to statistical physics. They failed because training them required sampling from intractable distributions. Even restricted Boltzmann machines (which simplified the architecture to make training feasible) were eventually abandoned in favor of other generative models.
That failure taught us something important: theoretical elegance doesn’t matter if you can’t optimize the model in practice. But it also revealed a constraint that might be temporary. Modern sampling methods (improved MCMC, learned samplers, etc.) might make Boltzmann machines practical again.
We’ll never know because nobody’s working on them anymore.
Capsule networks failed for similar reasons. The routing-by-agreement algorithm that made them theoretically appealing also made them computationally expensive and hard to train. But routing-by-agreement wasn’t the only possible way to implement the core ideas. We could have explored other routing mechanisms, other ways to represent part-whole relationships, other training procedures.
Instead, we abandoned the entire approach.
The challenge of evaluating alternative architectures has become even more complex with emerging technologies. Recent research from Quantum Zeitgeist examining hybrid quantum-classical neural networks reveals that while these models can match classical performance in limited instances, they frequently exhibit diminished metrics when quantum components are introduced. The study, conducted by researchers at RISC Software GmbH using medical signal data and various image types, demonstrates that the overhead associated with quantum-classical communication and data encoding often negates potential gains. A pattern that echoes the failures of earlier ambitious architectures that couldn’t overcome their fundamental computational constraints.
What Your Choice of Architecture Says About Your Assumptions
Every architecture embodies assumptions about the problem you’re solving. Most of the time, we don’t think about those assumptions explicitly. We choose transformers because they work well for language, then apply them to vision without asking whether the same assumptions make sense.
Transformers assume that relationships between elements can be learned from data through attention mechanisms. That’s reasonable for language, where word relationships are complex and context-dependent. It’s less obvious for vision, where spatial relationships have regular structure that CNNs encode directly. Vision transformers work, but they need more data than CNNs because they have to learn spatial structure that CNNs get for free.
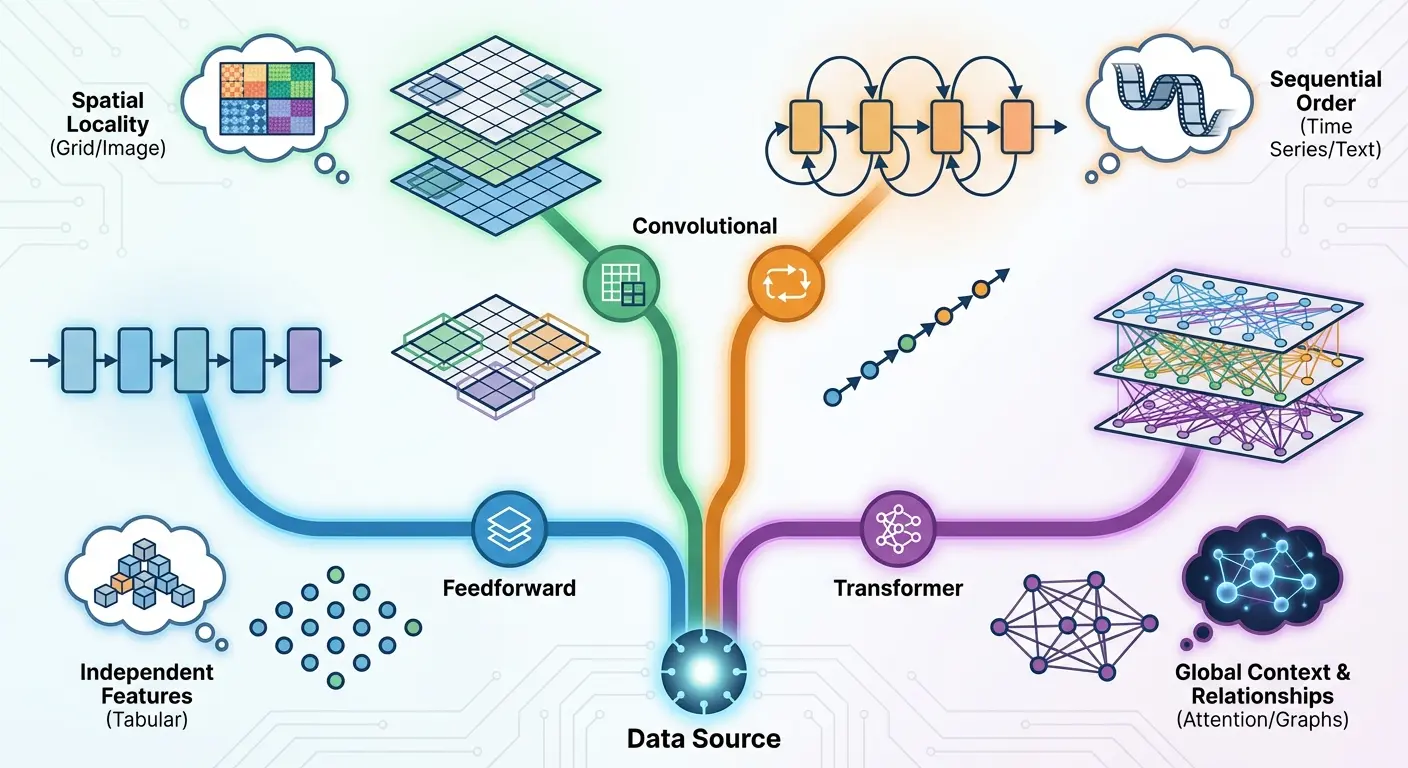
You’re trading architectural priors for flexibility. That trade makes sense if you have massive datasets and want to learn everything from data. It makes less sense if you’re data-constrained or if the architectural priors are correct for your problem.
Recurrent architectures assume sequential processing: each element depends on previous elements in a specific order. That’s true for some problems (time series, certain language tasks) and false for others (images, sets, graphs). When you use an RNN, you’re committing to that sequential assumption. Transformers relax that assumption by allowing all-to-all connections, which is more flexible but also more parameter-hungry.
A logistics company building a route optimization system initially chose a transformer architecture because it was “state-of-the-art” and their team had NLP experience. The model treated delivery locations as a sequence and used attention to learn relationships between stops. Performance was mediocre. The model required millions of historical routes to achieve 78% efficiency compared to human dispatchers.
A consultant pointed out they were ignoring crucial structure: delivery routes are fundamentally graph problems with spatial constraints (distance, traffic patterns, time windows). They redesigned using a graph neural network that explicitly encoded road networks, geographic proximity, and temporal constraints. With the same amount of training data, the GNN achieved 91% efficiency.
The transformer needed to learn from data what is neural network structure the GNN knew by design.
You have two options when designing a system: encode your knowledge about problem structure in the architecture, or give the model flexibility to learn that structure from data. Neither is universally correct.
CNNs for image classification are the canonical example of successful structure matching. Images have spatial structure, local patterns matter, and translation invariance is (mostly) true. CNNs encode all of that, which makes them sample-efficient for vision tasks. That was the right choice when data was limited and compute was expensive.
Vision transformers represent the opposite choice: ignore spatial structure, let the model learn everything. That requires more data and compute, but it’s more flexible. ViTs can learn to attend to distant spatial relationships that CNNs would miss. They can handle non-uniform spatial structure better. For problems where the assumptions behind CNNs don’t quite hold, ViTs might be better despite being less sample-efficient.
The decision depends on your constraints. If you have limited data, encode as much structure as you can in the architecture. If you have massive datasets and compute, flexibility might be worth the cost. If you need interpretability, explicit structure helps. If you need to handle diverse variations of a problem, flexibility helps.
Most teams don’t make this decision deliberately. They use whatever architecture is popular or has good pretrained models available. That’s understandable, but it means you’re inheriting someone else’s assumptions about the problem without checking whether they match your actual situation.
According to research on neural network architectures, convolutional neural networks were initially restricted to simple classification problems but have since advanced to domains like visual search engines, recommendation engines, and medical applications. Yet this expansion often happens through architectural adaptation rather than blind application of the same structure to fundamentally different problem types.
The real reason you’re using a transformer probably isn’t that you carefully analyzed your problem and determined that self-attention was the optimal mechanism. It’s that your team knows PyTorch, there’s a good pretrained model on Hugging Face, and you need results in three months.
Those are valid reasons. I’m not being sarcastic. Practical constraints matter as much as technical ones.
The problem is we don’t talk about them honestly. Papers present architecture choices as principled technical decisions when they’re often driven by convenience, available tools, or organizational momentum.

Your deployment environment constrains architecture choice more than you might admit. If you’re deploying on mobile devices, you can’t use massive transformer models regardless of their accuracy. If you need real-time inference, you can’t use architectures with high latency. If you’re in a regulated industry, you might need interpretability that rules out black-box models.
Team expertise is another hidden constraint. A team with strong computer vision background will gravitate toward CNN-based architectures because they understand them. A team from NLP will default to transformers. That’s rational (you want to use architectures you can debug and optimize) but it means architecture choice is partly determined by historical accident (who you hired) rather than problem requirements.
Timeline pressure kills architectural innovation. Exploring new architectures takes time. Fine-tuning a pretrained model gets you results quickly. When you’re under pressure to ship, you’ll choose the safe, proven option every time. That’s individually rational but collectively means we’re not exploring the architecture space as thoroughly as we should.
Finding the Right Architecture for Your Actual Problem
Start by articulating what you need. Not what benchmarks you want to beat, but what problem you’re solving and what constraints you’re operating under.
Do you need interpretability? That rules out deep black-box models and points toward architectures with explicit structure or attention mechanisms you can visualize. Do you have limited training data? That suggests architectures with strong inductive biases (CNNs for images, GNNs for graphs) rather than flexible but data-hungry transformers. Do you need to handle distribution shift? Look for architectures with modular components you can adapt or replace.
Consider your deployment constraints next. Latency requirements, memory limitations, energy budgets. These aren’t secondary considerations to optimize later. They’re fundamental constraints that should inform architecture choice from the start. A model that achieves 95% accuracy but can’t run in your deployment environment is useless.
Think about your data regime honestly. If you have millions of labeled examples and massive compute, you can use data-hungry architectures that learn everything from scratch. If you’re working with hundreds or thousands of examples, you need architectures that encode relevant structure or can leverage transfer learning effectively.
Your team’s expertise and available time matter too. An architecture that’s theoretically optimal but that your team can’t implement, debug, or optimize in the available time isn’t optimal for you. Sometimes the right choice is the architecture your team understands well, even if it’s not the most cutting-edge option.
|
Architecture Type |
Core Inductive Bias |
Best-Fit Problem Structure |
Sample Efficiency vs. Transformers |
When to Choose Over Transformers |
|---|---|---|---|---|
|
CNNs |
Spatial locality, translation invariance |
Grid-structured data with local patterns |
3-10x fewer samples for vision tasks |
Limited data, spatial structure dominates, need interpretable features |
|
GNNs |
Relational structure, permutation invariance |
Graph-structured data, variable-size inputs |
5-20x fewer samples for molecular tasks |
Explicit relationships matter, irregular topology, small datasets |
|
RNNs/LSTMs |
Sequential dependencies, temporal ordering |
Strictly ordered sequences with strong temporal causality |
2-5x fewer samples for certain time series |
True sequential processing needed, limited compute, online learning |
|
Capsule Networks |
Part-whole hierarchies, viewpoint invariance |
Objects with compositional structure |
Unclear (limited large-scale studies) |
Geometric reasoning critical, rotation/scale invariance essential |
|
Transformers |
Minimal bias, learn all structure from data |
Diverse tasks, large datasets available |
Baseline (requires most data) |
Massive data available, task structure unknown, maximum flexibility needed |
Why The Marketing Agency Thinks About Architecture Differently
We’ve talked to dozens of companies struggling with machine learning systems that don’t work in production. The pattern is usually the same: they chose an architecture because it was state-of-the-art on some benchmark, then discovered it didn’t fit their constraints.
Maybe it’s too slow for real-time inference. Maybe it requires too much labeled data and they only have a few hundred examples. Maybe it works great in the lab but falls
Maybe it’s too slow for real-time inference. Maybe it requires too much labeled data and they only have a few hundred examples. Maybe it works great in the lab but falls apart when the data distribution shifts slightly in production. Maybe nobody on the team can debug it when it fails.
When we work with clients at The Marketing Agency, the first question isn’t “what’s the best architecture?” It’s “what are your actual constraints?” What matters isn’t whether an architecture achieved state-of-the-art results on ImageNet. It’s whether it solves your specific problem within your specific constraints.
Sometimes that means using a “boring” architecture that’s well-understood and maintainable rather than the latest transformer variant. Sometimes it means designing custom architectures that encode domain knowledge instead of learning everything from scratch. Sometimes it means modular systems where you can swap components as requirements change.
If you’re struggling with architecture decisions or dealing with models that looked great in development but don’t work in production, we should talk. Contact The Marketing Agency to discuss your specific challenges and constraints.
Final Thoughts

The neural network architectures we use today aren’t the inevitable result of technical progress. They’re the result of specific choices made under specific constraints, optimizing for specific goals. Understanding those choices (and the alternatives we abandoned) helps you make better decisions for your own problems.
Transformers dominate because we prioritized flexibility and benchmark performance over sample efficiency and interpretability. CNNs persist in vision because their inductive biases are genuinely useful, even though more flexible architectures exist. Recurrent architectures faded because transformers parallelize better during training, not because sequential processing became irrelevant.
Each of these decisions made sense in context, but the context changes. What worked for academic researchers with massive compute budgets might not work for your production system with strict latency requirements. What worked for problems with millions of labeled examples might not work when you have hundreds.
The architectures in the graveyard (capsule networks, memory networks, neural module networks, neural ODEs) didn’t fail because they were bad ideas. They failed because they didn’t fit the priorities and constraints of the moment. Some of those ideas might deserve another look as our tools and requirements evolve.
Your architecture choice encodes assumptions about your problem, your data, your constraints, and your goals. Make those assumptions explicit. Question whether the assumptions that drove other people’s architecture choices apply to your situation. Don’t choose transformers because everyone else uses them. Choose them because self-attention genuinely makes sense for your problem and you can afford the computational cost.
The field’s obsession with benchmark performance has given us powerful architectures, but it’s also created blind spots. We’ve stopped exploring certain directions not because they’re unproductive but because they don’t immediately improve accuracy on standard datasets. We’ve sacrificed interpretability, sample efficiency, and robustness in pursuit of marginal performance gains.
You don’t have to make those same trade-offs. Understanding why certain architectures succeeded and others failed gives you the perspective to make deliberate choices rather than following the crowd. The best architecture for your problem might not be the one that won ImageNet. It might be the one everyone stopped working on five years ago because it didn’t scale the way transformers did.
Or it might be something nobody’s built yet because the incentives haven’t pointed in that direction. The architecture graveyard is full of ideas that might work brilliantly for problems the research community hasn’t prioritized.
Your problem might be one of them.