Picture this: You’re trying to understand why certain customers love your product while others bounce immediately. You’ve got user behavior data in one system, product info in another, and customer feedback scattered across three different platforms. Sound familiar?
That’s exactly the problem knowledge graphs solve. Instead of hunting through disconnected databases, you get a unified view where every piece of information connects to create a complete picture.
The Quick Version
Knowledge graphs connect your data like a web of relationships. Think of it as turning a pile of business cards into a detailed map of who knows whom, what they do, and how they’re all connected. When done right, this transforms how you find information, make decisions, and serve customers.
Knowledge graphs have become increasingly critical in 2025, with businesses that optimize their knowledge graphs experiencing increased traffic as users are more likely to engage with content that appears prominently in search results.
Starting With Solid Foundations
Most knowledge graph projects fail before they begin. Not because the technology is flawed, but because teams rush into building without understanding what they’re actually creating.
A knowledge graph isn’t just a fancy database. It’s a way of modeling how things in your business relate to each other. Get this foundation wrong, and every optimization technique in the world won’t save you.
Making Sense of Connections
Think about how you naturally understand information. When someone mentions “Apple,” your brain instantly considers context clues. Are we talking about fruit, the tech company, or maybe a record label? You make these distinctions effortlessly by considering surrounding information.
Knowledge graphs work similarly. They use mathematical principles from graph theory to represent entities (like companies, people, or products) and their relationships (works for, competes with, purchased by).
The Entity Resolution Challenge
Here’s where most projects hit their first roadblock. You’ll discover that “Apple Inc.” appears as “Apple Computer” in legacy systems and just “Apple” in newer databases. Your system needs to figure out these refer to the same company without accidentally merging Apple Inc. with Apple Records.
I learned this lesson the hard way on a healthcare project. We had doctors appearing under multiple variations of their names across different systems. Dr. John Smith became J. Smith, MD in one database and John A. Smith in another. Without proper entity resolution, we couldn’t track patient care across the network.
The solution involves confidence scoring. Start with exact matches, then expand to fuzzy matching that considers shared attributes like license numbers or hospital affiliations. But be careful – there are probably dozens of Dr. John Smiths out there.
Consider a healthcare knowledge graph where “Dr. John Smith” appears as “J. Smith, MD” in one system and “John A. Smith” in another. Your entity resolution system needs to evaluate shared attributes like medical license numbers, hospital affiliations, and specialty areas to determine if these represent the same physician while avoiding false matches with other doctors named John Smith.
Designing for Different Relationship Types
Not all connections are created equal. The relationship between a company and its CEO (one-to-one) needs different optimization than the relationship between products and categories (many-to-many).
Here’s what I’ve learned works for relationship cardinality optimization:
|
Relationship Type |
Indexing Strategy |
Use Case Example |
Performance Impact |
|---|---|---|---|
|
One-to-One |
Simple hash index |
Person to Social Security Number |
Low overhead |
|
One-to-Many |
Forward index on parent entity |
Company to Employees |
Medium overhead |
|
Many-to-Many |
Junction table with dual indexing |
Products to Categories |
High overhead |
|
Hierarchical |
Tree-based indexing |
Organization Structure |
Variable based on depth |
Building Smart Ontologies
Ontologies serve as the blueprint for your knowledge domain. They define the types of entities you’ll work with and how they can relate to each other. The challenge is balancing expressiveness with computational efficiency.
Starting with established upper ontologies provides a solid foundation. Schema.org and FOAF offer proven vocabularies that you can extend with domain-specific terms that match your particular use case.
Well-designed ontologies evolve gracefully. You can start simple and add complexity as your understanding of the domain deepens and your requirements become more sophisticated.
Getting Your Data Architecture Right
The biggest mistake I see teams make is treating data integration as an afterthought. You’re dealing with CSV exports, API feeds, legacy databases, and unstructured documents – all needing to become part of your unified graph.
Most organizations underestimate the complexity of this integration work. You’re dealing with inconsistent data formats, varying quality levels, and conflicting information that needs to be reconciled intelligently.
Schema Mapping Reality Check
Your source systems will change. APIs get updated, database schemas evolve, and new data sources appear. Build your mapping rules to handle this evolution gracefully, or you’ll be constantly fixing broken connections.
Converting different data formats into standardized graph representations is where most projects hit their first major roadblock. You’re dealing with CSV files, JSON APIs, relational databases, and unstructured text – all needing to become nodes and edges in your graph.
Recent trends in entity SEO demonstrate the practical importance of schema mapping. As noted in a Knowledge Graphs & Entities for SEO Search Engine Land analysis, many companies are successfully using entity-based strategies by establishing relationships between new entities and connecting existing entities to Google’s Knowledge Graph through proper schema markup implementation.
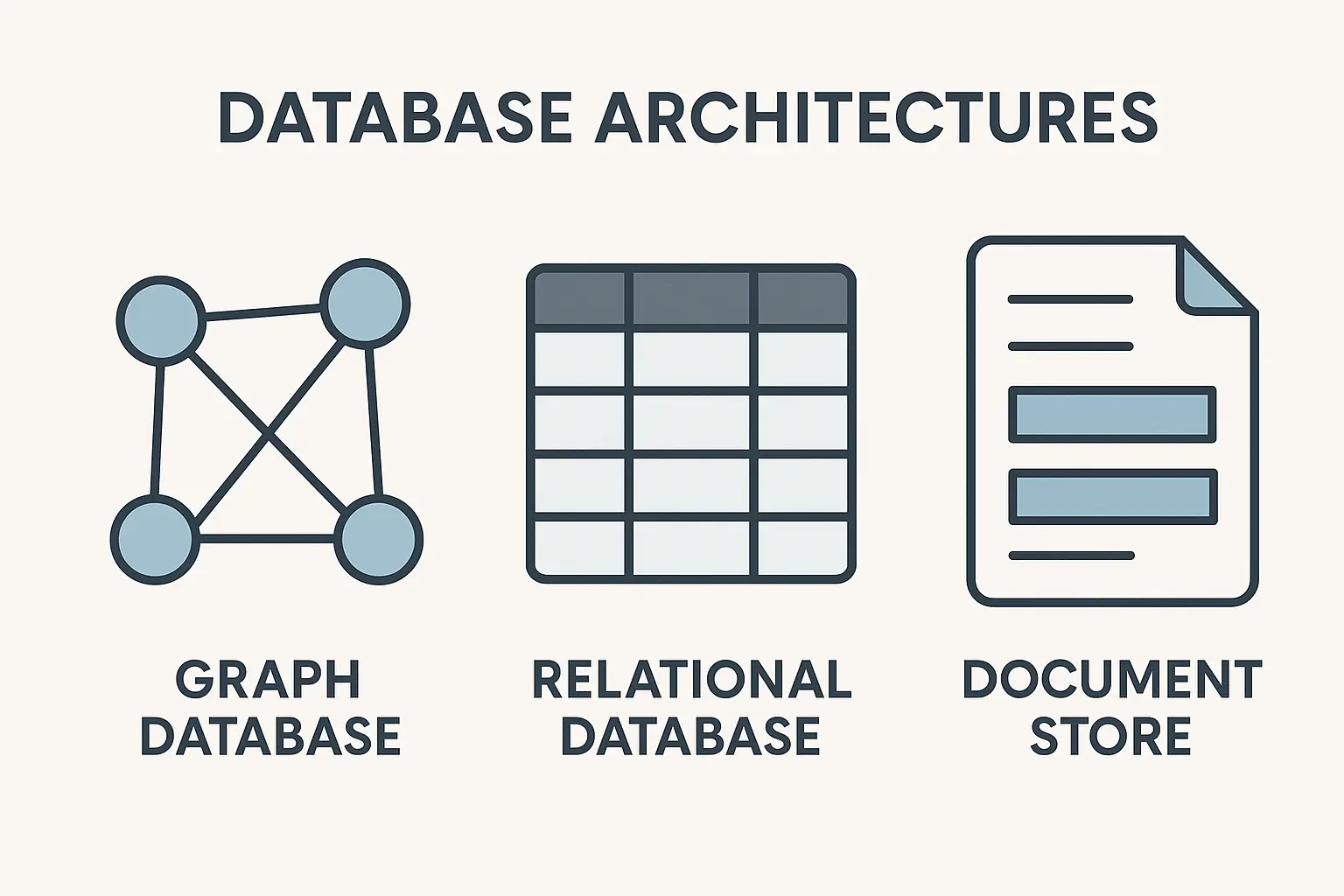
Storage Decisions That Matter
How you store and index your graph data directly impacts query performance and scalability. Different storage approaches work better for different query patterns, so understanding your access patterns is crucial for making the right architectural decisions.
Triple Store Optimization
RDF triple stores are the traditional approach for storing semantic data. The challenge is configuring them properly with the right indexing strategies and partitioning schemes to handle your specific workload.
Most performance issues come from inadequate indexing. You need indexes that support your most common query patterns, but too many indexes slow down write operations. Finding this balance requires careful analysis of your query workload and update frequency.
Choosing the Right Graph Database
Native graph databases excel when you’re traversing multiple relationships – like finding all suppliers connected to delayed shipments in the last quarter. Traditional databases work better for simple lookups – like finding a customer’s current address.
Consider factors such as ACID compliance, horizontal scaling capabilities, and the complexity of your relationship traversals when making this decision. The wrong choice here haunts projects for years.
Smart Memory Management
Intelligent caching strategies can dramatically improve query performance by keeping frequently accessed subgraphs in memory. The trick is identifying which parts of your graph get accessed most often and prioritizing them for caching.
You’ll also need to consider cache invalidation strategies when your underlying data changes. Stale cache data can lead to inconsistent query results, which can be worse than slower performance from cache misses.
Making Queries Actually Fast
A beautiful knowledge graph is worthless if queries take forever. Performance optimization becomes critical as you scale from thousands to millions of entities.
Extracting information efficiently from knowledge graphs requires understanding both traditional graph query languages and modern vector-based retrieval methods. The combination of these approaches creates powerful hybrid systems that can handle both precise factual queries and semantic similarity searches.
SPARQL Without the Pain
SPARQL is the standard query language for semantic data, but most developers write queries that perform terribly. The secret is understanding how query engines think.
Start with your most restrictive conditions first. If you’re looking for “software engineers in Toronto who joined after 2020,” filter by location and date before checking job titles. This reduces the working set early and dramatically improves performance.
Query Plan Optimization
Query engines generate execution plans that determine the order of operations for your SPARQL queries. Understanding these plans helps you write queries that execute efficiently, especially when dealing with complex joins across multiple graph patterns.
Understanding selectivity is crucial – starting with the most restrictive conditions first to reduce the working set size early in the query execution. This principle applies whether you’re working with SPARQL, Cypher, or any other graph query language.
Query Optimization Checklist:
-
Start with most selective triple patterns
-
Use LIMIT clauses to prevent runaway queries
-
Avoid OPTIONAL clauses in nested loops
-
Index frequently queried predicates
-
Monitor query execution plans
-
Cache common subqueries
Federated Query Processing
Running queries across distributed knowledge graphs introduces latency and consistency challenges. You’re dealing with network delays, partial failures, and potentially inconsistent data across different graph endpoints.
Implementing timeout strategies and fallback mechanisms helps handle scenarios where remote endpoints become unavailable during query execution. Your system needs to degrade gracefully rather than failing completely when one data source goes offline.
The Vector RAG Revolution
Here’s where knowledge graphs get really interesting. Traditional exact-match queries are great for finding specific facts. But what about discovering related information that might be relevant but not obviously connected?
Vector embeddings solve this by capturing semantic relationships. Your system can find relevant information even when queries don’t match stored data exactly.
Modern knowledge graphs benefit enormously from vector embeddings that capture semantic similarities between entities and relationships. This enables approximate reasoning and similarity-based retrieval that complements traditional exact-match queries.
Knowledge Graph Embeddings
Training vector representations of your graph entities opens up new possibilities for similarity search and recommendation systems. These embeddings capture semantic relationships that might not be explicitly represented in your graph structure.
The challenge is choosing the right embedding technique for your specific domain and ensuring the embeddings stay current as your graph evolves. Stale embeddings can lead to poor recommendations and irrelevant search results.
Vector RAG Implementation
Combining knowledge graphs with vector databases creates powerful retrieval-augmented generation systems. You get the factual accuracy of structured knowledge with the semantic search capabilities of vector similarity.
This hybrid approach works particularly well for question-answering systems where you need both precise factual information and contextually relevant supporting details. The system can find exact facts while also surfacing related information that provides helpful context.
Recent research shows significant performance improvements with different RAG approaches. A comparative analysis of VectorRAG, GraphRAG, and HybridRAG techniques revealed that GraphRAG excelled in correctness and overall performance, while HybridRAG offered a balanced approach by combining the strengths of both vector and graph-based retrieval methods, as detailed in NVIDIA’s analysis of LLM-driven knowledge graphs.
|
RAG Technique |
Strengths |
Weaknesses |
Best Use Cases |
|---|---|---|---|
|
VectorRAG |
Fast semantic search, good for similarity |
Limited reasoning capabilities |
Content recommendation, semantic search |
|
GraphRAG |
Superior accuracy, excellent reasoning |
Higher computational complexity |
Complex queries, multi-hop reasoning |
|
HybridRAG |
Balanced performance, combines both approaches |
Implementation complexity |
Enterprise applications, regulated domains |
Effective vector RAG implementation requires comprehensive marketing strategy integration to ensure that your knowledge graph-powered systems align with customer journey mapping and content personalization efforts.
Learning from Google’s Playbook
Google’s Knowledge Graph processes billions of web pages to extract entities and relationships, then uses this information to power search features. Their approach offers valuable lessons for enterprise implementations.
Understanding how major search engines use knowledge graphs provides insights into best practices for enterprise implementations. Google’s approach demonstrates how to scale knowledge systems while maintaining accuracy and relevance for billions of queries.
How Search Engines Think
When you search for “Apple CEO,” Google doesn’t just match keywords. It understands you’re asking about the current chief executive of Apple Inc. and can provide Tim Cook’s information along with relevant context.
This works because Google’s knowledge graph connects entities through verified relationships. They score confidence based on source authority and cross-reference information across multiple sources.
Knowledge graphs power the rich snippets and direct answers you see in search results. Understanding how search engines extract and utilize structured data helps you optimize your content for better visibility and user experience.
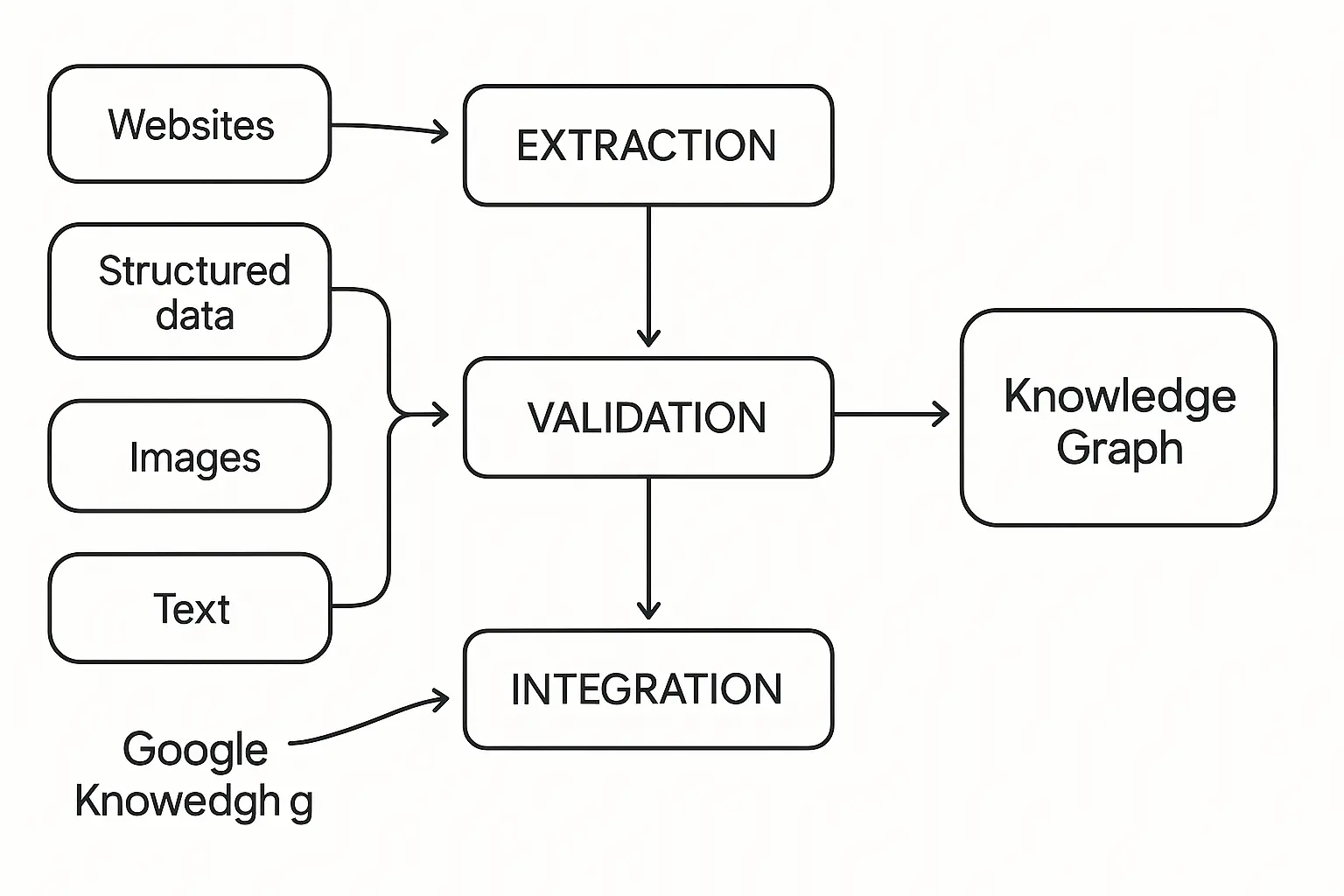
Google Knowledge Graph Architecture
Google’s system processes web content to extract entities and relationships, then scores the confidence of these extractions based on source authority and consistency across multiple sources. This creates a constantly evolving knowledge base that powers search features.
The technical infrastructure handles real-time updates while maintaining consistency across billions of entities and relationships. This requires sophisticated conflict resolution and data fusion techniques that can handle contradictory information from different sources.
Structured Data That Works
Implementing Schema.org markup helps search engines understand your content, but consistency matters more than perfection. Choose the right schema types for your content and implement them uniformly across your site.
Implementing Schema.org markup and JSON-LD in your content helps search engines understand your information and potentially feature it in knowledge graph-powered results
Implementing Schema.org markup and JSON-LD in your content helps search engines understand your information and potentially feature it in knowledge graph-powered results. This structured data acts as a bridge between your content and search engine knowledge systems.
A local restaurant implementing Schema.org markup would include structured data for their business hours, location, menu items, and customer reviews. This enables Google to display rich snippets showing operating hours, star ratings, and popular dishes directly in search results, significantly improving click-through rates and local visibility.
When implementing structured data for search engines, successful branding initiatives must consider how knowledge graph optimization impacts brand entity recognition and search visibility across multiple touchpoints.
Enterprise Applications
The same principles that power Google’s search work inside organizations. Connect your project data, employee information, and business processes to enable discovery that crosses traditional departmental boundaries.
Organizations can implement knowledge graph principles to improve internal information discovery and decision-making processes. These systems connect disparate data sources and enable employees to find relevant information across departmental boundaries.
Internal Knowledge Discovery
Instead of employees searching isolated systems, they can discover connections between projects, people, and resources they never knew existed. The key is balancing discoverability with security requirements.
Creating searchable knowledge bases that understand relationships between different types of internal information transforms how employees access organizational knowledge. Instead of searching through isolated systems, they can discover connections between projects, people, and resources.
This requires careful attention to data governance and access controls to ensure sensitive information remains properly protected. You need to balance discoverability with security requirements, which can be challenging in complex organizational structures.
Automated Reasoning and Inference
Rule-based systems and machine learning models can derive new knowledge from existing graph relationships. This automated reasoning helps identify potential opportunities, risks, and inconsistencies that human analysts might miss.
The challenge is balancing automation with human oversight to ensure the inferred knowledge is accurate and actionable. False positives in automated reasoning can lead to poor business decisions if not properly validated.
The telecommunications industry is pioneering advanced knowledge graph applications for network resilience. Knowledge Graphs: The Lifeline for Resilient Autonomous Networks Nokia’s recent analysis demonstrates how knowledge graphs enable emergency management solutions that constantly monitor for natural disasters and prioritize service restoration for critical infrastructure during emergencies.
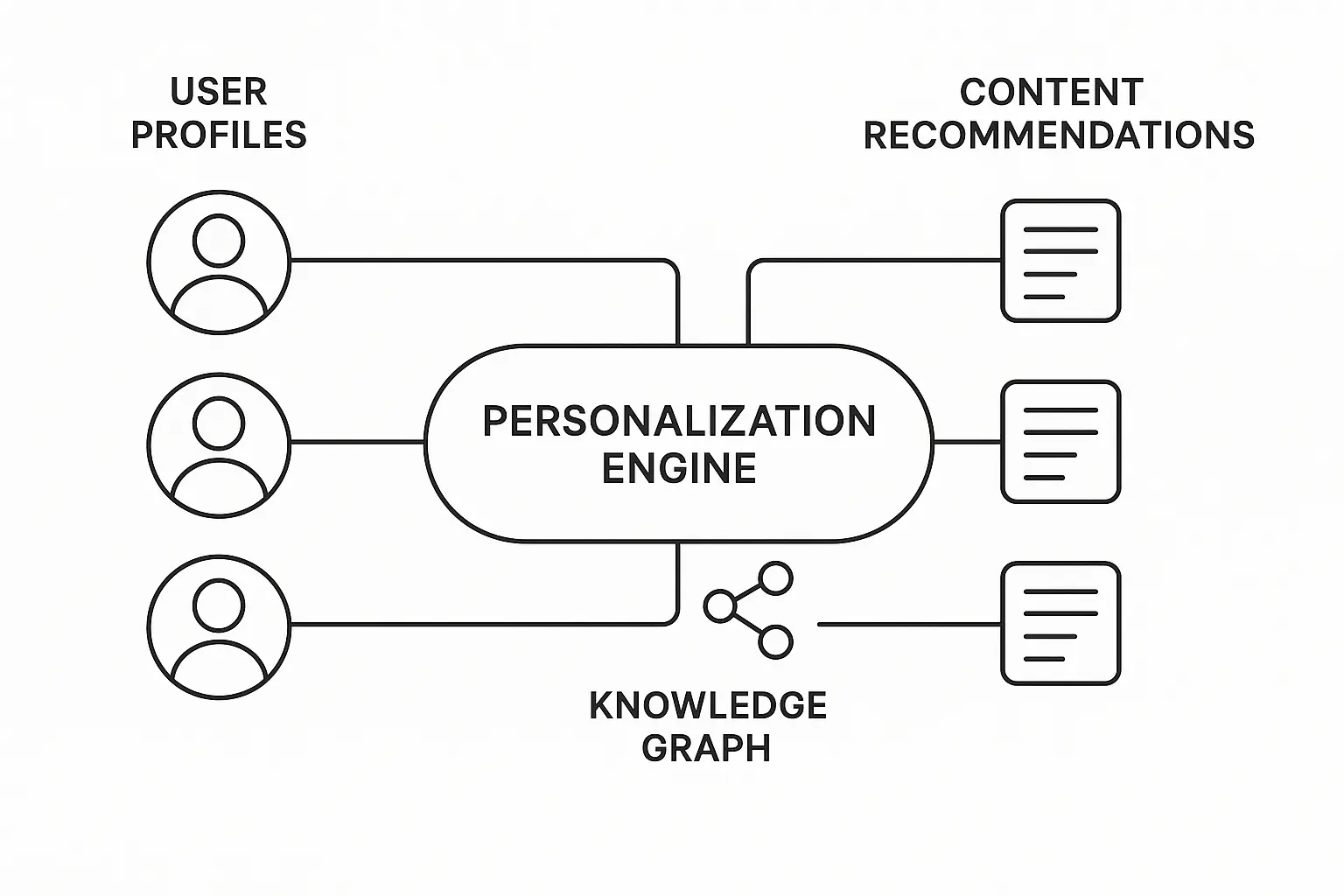
Content Personalization Engines
Knowledge graphs enable sophisticated recommendation systems that understand both content relationships and user preferences. This goes beyond simple collaborative filtering to consider the semantic connections between different types of content.
User behavior data combined with content knowledge graphs creates personalization that feels intuitive and helpful rather than intrusive. The system understands why certain content pieces are related and can make intelligent recommendations based on these relationships.
Content personalization systems Content personalization systems benefit significantly from comprehensive design thinking approaches that ensure knowledge graph-driven recommendations maintain visual consistency and user experience coherence across all customer touchpoints.
Advanced Techniques That Actually Work
Once your foundation is solid, machine learning integration and distributed architectures enable systems that handle massive scale while continuously improving.
Cutting-edge knowledge graph optimization involves integrating machine learning for automation and implementing distributed architectures for scale. These advanced techniques enable systems that can handle massive datasets while continuously improving through automated learning processes.
Automation That Makes Sense
Natural language processing can automatically extract entities and relationships from documents, emails, and other unstructured content. But the balance between automation and accuracy is critical.
Artificial intelligence transforms knowledge graphs from static repositories into dynamic, learning systems. Machine learning automates the most time-consuming aspects of knowledge graph maintenance while enabling predictive capabilities that weren’t possible with traditional approaches.
Too strict, and you miss valuable information. Too loose, and you pollute your graph with incorrect connections. The sweet spot involves training models on your specific domain while maintaining high precision standards.
Automated Knowledge Extraction
Natural language processing and computer vision can automatically identify entities and relationships from unstructured content. This automation dramatically reduces the manual effort required to keep knowledge graphs current and comprehensive.
The key is training models that understand your specific domain while maintaining high precision to avoid polluting your graph with incorrect information. Organizations struggle with this balance – too strict and you miss valuable information, too loose and you introduce noise that degrades system performance.
Recent advances in LLM-driven knowledge extraction show remarkable improvements in accuracy. In experimental workflows, fine-tuning smaller models using techniques such as Low-Rank Adaptation (LoRA) achieved significant improvements in completion rates and accuracy for triplet extraction, as demonstrated in NVIDIA’s research on optimized knowledge graph generation.
Machine Learning Integration Pipeline:
-
Document Preprocessing
-
Text chunking and segmentation
-
Language detection and normalization
-
Quality filtering and validation
-
-
Entity Recognition
-
Named entity recognition (NER)
-
Entity linking and disambiguation
-
Confidence scoring
-
-
Relationship Extraction
-
Dependency parsing
-
Relation classification
-
Triple formation and validation
-
-
Post-Processing
-
Duplicate detection and merging
-
Consistency checking
-
Quality assurance validation
-
Graph Neural Networks
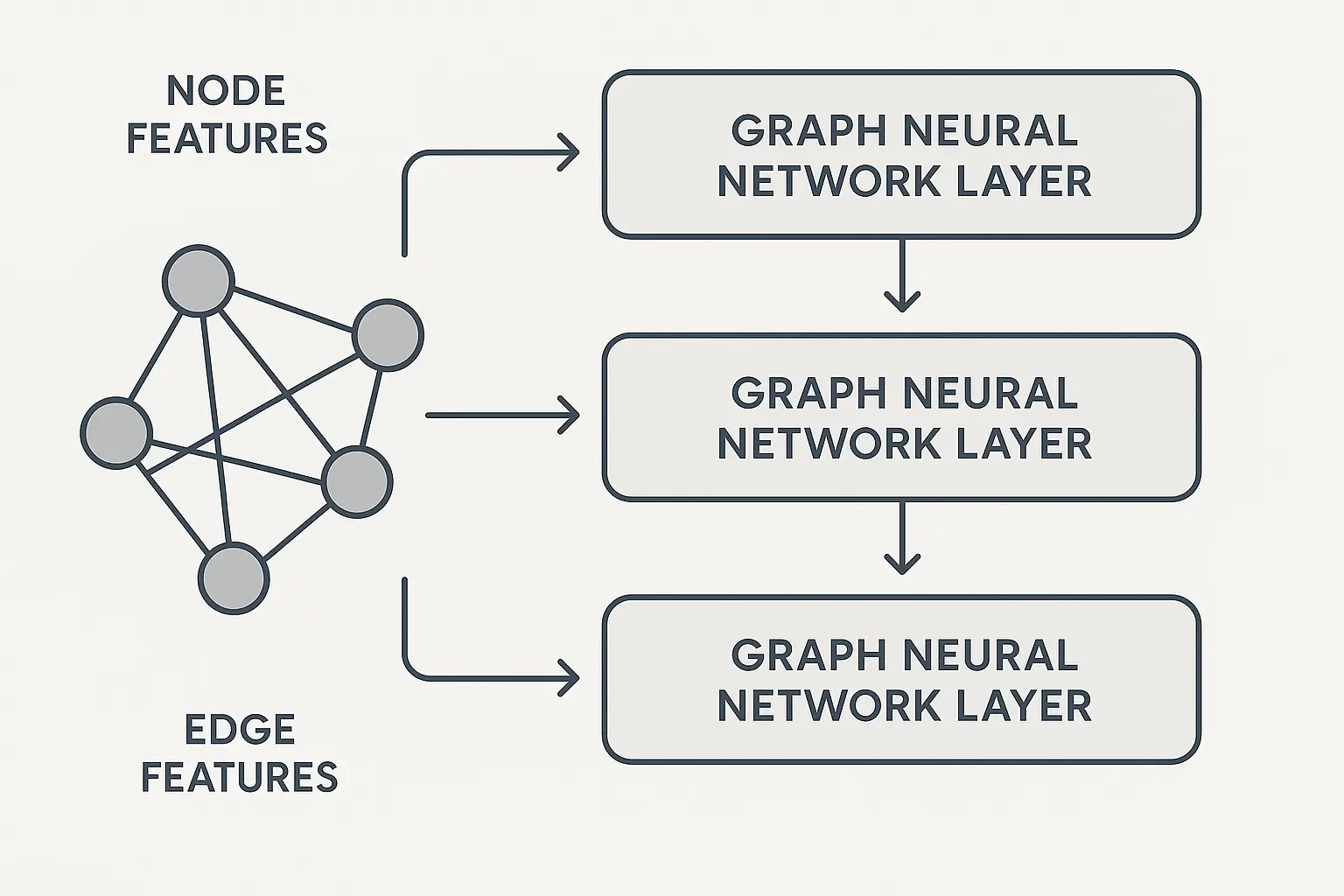
Deep learning architectures designed specifically for graph data enable sophisticated analysis tasks such as node classification and link prediction. These models can identify patterns in your graph structure that traditional algorithms might miss.
Graph neural networks excel at tasks that require understanding both local node features and global graph structure simultaneously. They can predict missing relationships, classify entities based on their neighborhood characteristics, and even detect anomalies in graph structure.
Scaling Without Breaking
Distributing knowledge graphs across multiple servers while maintaining performance requires careful partitioning strategies. Keep frequently co-accessed entities on the same partition to minimize cross-server communication.
Scaling knowledge graphs to handle millions of entities and billions of relationships while maintaining sub-second query response times requires careful engineering and architectural decisions. The solutions involve both distributed processing and intelligent optimization strategies.
A global e-commerce platform might partition by geography, keeping regional product, customer, and inventory data together while maintaining global connectivity for international operations.
Distributed Graph Processing
Partitioning large knowledge graphs across multiple machines minimizes cross-partition communication while maintaining query performance. The challenge is choosing partitioning strategies that align with your query patterns.
Graph partitioning algorithms try to keep frequently co-accessed entities on the same partition, but this becomes increasingly difficult as graphs grow and query patterns evolve. You need strategies that can adapt to changing access patterns without requiring complete repartitioning.
A global e-commerce platform might partition their product knowledge graph geographically, keeping products, customers, and inventory data for each region on dedicated servers. This reduces cross-partition queries for location-based recommendations while maintaining global connectivity for international shipping and product discovery across regions.
Real-time Updates
Some applications need immediate consistency, others can tolerate eventual consistency. Understanding these requirements upfront prevents architectural decisions you’ll regret later.
Managing concurrent updates to knowledge graphs while ensuring data consistency requires sophisticated coordination mechanisms. You need to balance consistency guarantees with performance requirements based on your specific use case.
Define consistency requirements per use case, implement conflict resolution, and always plan for rollback scenarios. Test concurrent update handling before you need it in production.
The scale of modern knowledge graph operations is impressive. Businesses that optimize their knowledge graphs experience increased traffic, as users are more likely to engage with content that appears prominently in search results, according to PingCAP’s 2025 optimization guide, demonstrating the direct business impact of proper knowledge graph implementation.
Real-time Update Strategy Checklist:
-
Define consistency requirements per use case
-
Implement conflict resolution mechanisms
-
Set up change propagation workflows
-
Monitor update latency and throughput
-
Plan for rollback and recovery scenarios
-
Test concurrent update handling
-
Establish data validation checkpoints
How The Marketing Agency Can Help
Drowning in disconnected data that makes understanding your customers feel impossible? We get it. Your CRM talks to your email platform, but neither connects to your website analytics or social media insights. You’re making decisions with half the picture.
That’s exactly what we solve at The Marketing Agency. We build knowledge graph systems that finally connect all your marketing touchpoints into one intelligent system. Instead of jumping between dashboards, you get a unified view of how customers actually interact with your brand.
Our team has hands-on experience with vector RAG systems that supercharge competitive analysis. We help you spot market opportunities and customer behavior patterns that your competitors are missing. It’s like having x-ray vision for your market data.
We’ve helped companies discover that their highest-value customers follow completely different paths than they assumed. One client found that their best customers actually started with blog content, not their main product pages. That insight alone transformed their content strategy and boosted conversions by 40%.
Ready to stop guessing and start knowing? Let’s talk about connecting your data dots into a complete customer picture. Check out our case studies to see how knowledge graph optimization transforms marketing analytics from guesswork into precision.

Final Thoughts
Knowledge graphs aren’t just the next shiny tech trend – they’re becoming essential infrastructure for businesses that want to actually understand their data instead of just collecting it.
The techniques we’ve covered transform how you think about information. Instead of isolated databases that require manual detective work to connect insights, you get systems that understand relationships and surface connections automatically.
But here’s the thing: success isn’t about implementing every advanced technique we discussed. It’s about starting with solid foundations, understanding your specific needs, and building systems that grow with your business.
The companies winning with knowledge graphs aren’t necessarily the ones with the most sophisticated implementations. They’re the ones that solve real problems for real users while keeping their systems maintainable and scalable.
Your data already contains the insights you need to outperform competitors and better serve customers. Knowledge graphs just make those insights discoverable instead of buried in disconnected systems.
The future belongs to organizations that can turn their data into understanding, not just storage. Knowledge graphs provide the infrastructure for that transformation.