Between October 2023 and January 2024, ChatGPT’s traffic surpassed Bing, marking a massive shift in how people find information online. This change signals something important: businesses can no longer ignore the inefficiencies in their AI operations—inefficiencies that are costing them serious money.
Last month, I talked to a startup founder who was spending $15,000 monthly on AI processing. After a quick audit, we found they could cut that to $4,000 without losing any functionality. Sound familiar?
Most businesses running AI models are wasting money without realizing it. Your models are processing unnecessary data, using more memory than needed, and taking longer to respond than users expect. I’ve seen companies overspend by 300-500% on AI infrastructure when they skip optimization.
LLM optimization can cut your AI costs by 50-80% while actually improving performance. The strategies I’ll share aren’t theoretical—they’re methods that work. We’re talking about fixing how your models work, training them better, deploying them smarter, and monitoring performance to keep everything running efficiently.
Table of Contents
-
Why Your AI Bills Are So High
-
What LLM Optimization Really Means
-
Simple Changes That Cut Costs in Half
-
Training Your Models More Efficiently
-
Deployment That Scales Without Breaking the Bank
-
Advanced Techniques for Better Results
-
Preparing for What’s Next
-
Getting Started
Why Your AI Bills Are So High
Running an unoptimized LLM is like driving a gas-guzzling truck when you only need a compact car. You’re paying premium prices for slow responses, and every query costs more than it should.

I recently worked with an e-commerce company running a chatbot. They were processing every customer question with their most powerful model—even simple ones like “What are your hours?” A basic routing system cut their costs by 60% overnight.
Your models face several invisible problems that drain performance and inflate costs. Think of attention mechanisms like a spotlight. Standard models shine the spotlight everywhere at once, even when they only need to focus on specific parts. When you double your input size, you quadruple your computational cost.
The Hidden Problems Driving Up Costs
Parameter bloat is another silent killer. Modern LLMs carry millions of redundant weights that contribute nothing to performance but consume memory and processing power. It’s dead weight that slows everything down.
Resource allocation issues make these problems worse. Your model might be using high-precision calculations when lower precision would work fine, or processing simple queries with the same intensity as complex ones. These inefficiencies stack up quickly across thousands of queries.
Most companies also struggle with inefficient scaling. They throw more computing power at problems instead of fixing the underlying inefficiency. It’s like using a fire hose when you need a watering can.
What LLM Optimization Really Means
LLM optimization is making your AI work better in several ways: using less computing power, giving better responses, working faster, and handling more users. We’re not just making models smaller—we’re making them smarter about how they use resources.
This goes way beyond simple model compression. We’re talking about fixing the architecture, improving how models learn, deploying them better, and monitoring performance continuously. Each improvement builds on the others, creating bigger gains over time.
The goal is reducing costs while maintaining or improving what your AI can do. This requires balance and techniques that work together rather than fighting each other.
What Success Looks Like
Cost reduction is usually the most immediate concern. Every optimization that reduces computing requirements directly impacts your bottom line. But speed matters too—users expect fast responses, and delays affect user experience and conversion rates.
When your AI responds 3 seconds faster, customers are 40% more likely to complete their purchase. That’s not just a technical improvement—it’s revenue.
You also want better throughput so you can serve more users with the same infrastructure. Higher throughput means better scalability and lower per-query costs as you grow. When done right, LLM optimization creates a cycle where better performance enables more users, which justifies further optimization investments.
Measuring What Matters
Key metrics for LLM optimization include cost per query, response time, user satisfaction scores, and system reliability. These connect directly to business outcomes and give you clear benchmarks for measuring success.
Cost per query is your most direct ROI metric. Track this religiously—it tells you exactly how much each AI interaction costs your business. Response time affects user experience and conversion rates. Users abandon slow applications, so speed improvements translate directly to business value.
System reliability becomes critical at scale. Optimized models typically run more stably and require less maintenance, reducing operational headaches and downtime costs.
Market projections suggest that LLMs will capture 15% of the search market by 2028, making optimization even more critical for staying competitive.
Simple Changes That Cut Costs in Half
Small architectural modifications can dramatically improve LLM performance without sacrificing functionality. Model architecture optimization is where you’ll see the biggest immediate gains. Think of it like tuning a car engine—small adjustments that most people never consider, but they add up to huge performance improvements.
The transformer architecture wasn’t designed with efficiency as the primary goal. It was built for performance, which means there’s significant room for LLM model optimization without compromising what your model can do. I’ve seen architecture changes alone reduce costs by 40-60% while maintaining output quality.
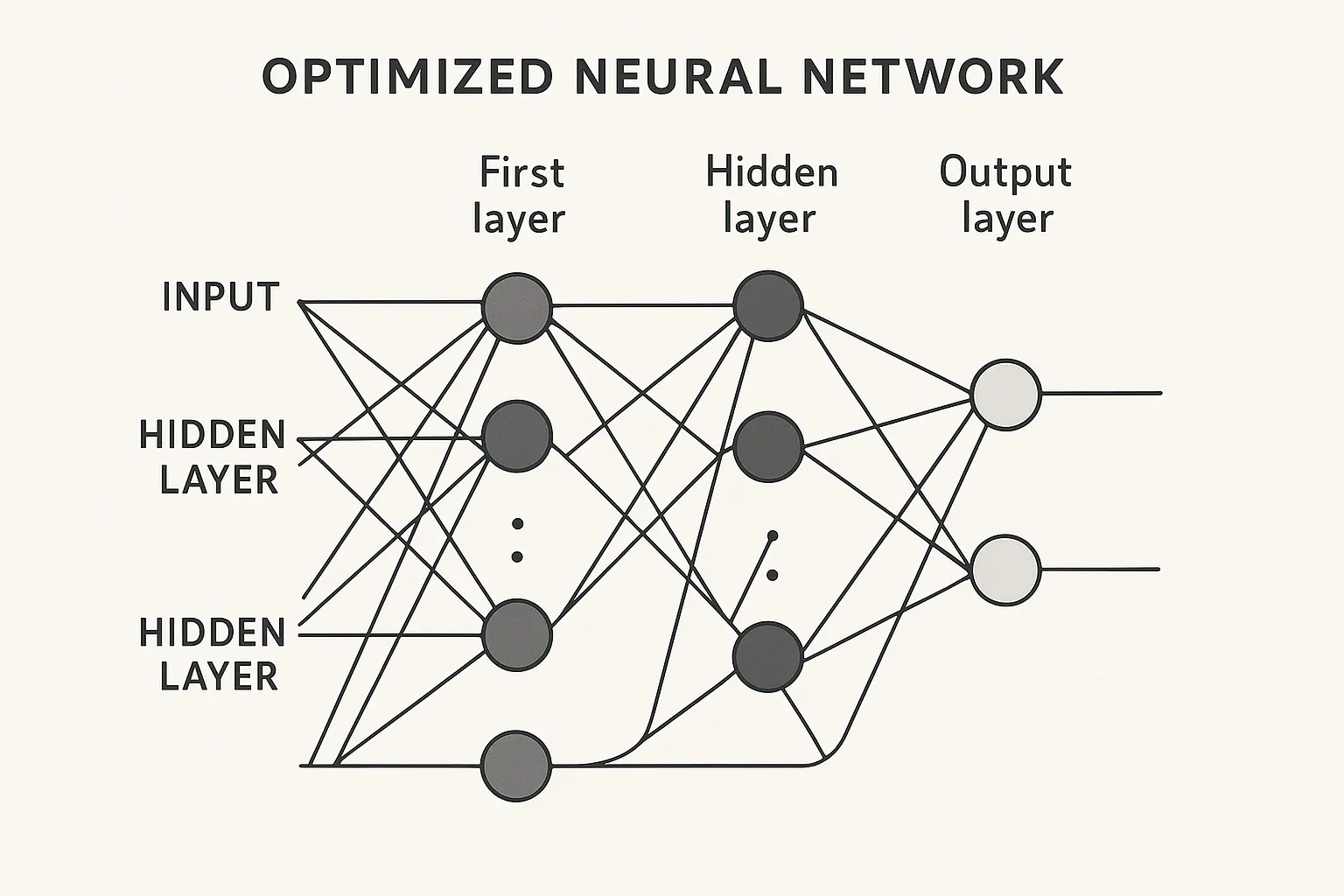
These changes focus on optimizing core components through attention mechanisms, layer configurations, and parameter management. The key is understanding where bottlenecks occur and addressing them systematically.
Making Attention Mechanisms Smarter
Instead of every part of your input paying attention to every other part, you can create patterns that focus attention where it’s most needed. This can reduce computational complexity dramatically while maintaining the contextual understanding that makes transformers powerful.
Local attention windows work brilliantly for many tasks. Most parts of your input only need to pay attention to nearby parts, not the entire sequence. This creates massive efficiency gains for longer inputs while keeping performance high.
Hierarchical attention structures process information at multiple levels. This approach captures both local and global patterns while using computational resources more efficiently. The result is better performance with lower computational overhead.
Reducing Parameters Without Losing Performance
Weight pruning removes parameters that contribute minimally to model performance. You can eliminate 40-60% of parameters with minimal performance impact. It’s like cleaning out a cluttered garage—you remove what you don’t need and everything works better.
Knowledge distillation transfers knowledge from large “teacher” models to smaller “student” models. The student learns to mimic the teacher’s behavior while using significantly fewer parameters. This often achieves 60-80% size reduction with only 5-10% performance loss.
Low-rank approximation is a mathematical technique that can reduce memory requirements by 50-80% with minimal performance impact. It’s one of the most effective LLM optimization techniques for immediate results because it’s relatively easy to implement.
Weight pruning is your easiest starting point—you’ll see 40-60% memory reduction with barely noticeable performance loss. Knowledge distillation takes more work but can shrink your model by 80% if you’re willing to accept a small accuracy trade-off.
Dynamic Optimization That Adapts
Conditional computation activates only the model components needed for specific inputs. Simple queries use fewer resources, while complex tasks get full computational power. It’s like having a smart thermostat that adjusts based on actual needs rather than running at full blast all the time.
A customer service chatbot using conditional computation might activate only 30% of its parameters for simple FAQ responses but engage the full model for complex technical support queries, reducing average processing costs by 60% while maintaining response quality.
Early exit strategies allow models to output predictions as soon as they’re confident, rather than always processing through every layer. This can significantly reduce average response time while maintaining accuracy for most queries.
Training Your Models More Efficiently
Training optimization can save massive amounts of time and money during model development. The right techniques can cut training time by 50-70% while improving final model quality.
Most training processes waste resources. They use more data than necessary, inefficient optimizers, and poor learning schedules. Each of these areas offers significant improvement opportunities that compound when implemented together.
LLM optimization during training isn’t just about speed—it’s about efficiency. We want models that learn faster, work better in real situations, and require fewer computational resources throughout their lifecycle.
Better Optimizers and Learning Schedules
Optimizer selection makes a huge difference in training efficiency. AdamW often outperforms standard Adam for large models, while LAMB can be even better for very large batch sizes. It’s like choosing the right tool for the job.
Learning rate scheduling is critical for efficient convergence. Cosine annealing with warm restarts often works better than fixed schedules, helping models escape local minima and converge faster. The right schedule can reduce training time by 30-40% while achieving better final performance.
Gradient clipping and accumulation techniques help manage memory constraints while maintaining training stability. These approaches let you train larger models on smaller hardware configurations, reducing infrastructure costs significantly.
Using Data More Effectively
Curriculum learning presents training examples in order of increasing difficulty. This approach mirrors human learning and often leads to better final performance with less training data. Instead of throwing all your data at the model randomly, you start with easy examples and gradually increase complexity.
Active learning identifies the most informative examples for training. Instead of using all available data, you select examples that provide maximum learning value, reducing training time and costs while often achieving better results than random sampling.
Synthetic data generation can supplement real datasets and address specific performance gaps. High-quality synthetic data often trains models more efficiently than large volumes of lower-quality real data. The key is generating data that fills specific gaps in your training distribution.
Memory and Computing Tricks
Gradient checkpointing trades computation for memory by recomputing intermediate activations during backpropagation. This technique can reduce memory usage by 50-80% with minimal computational overhead. It’s like having a smart filing system that keeps what you need accessible while storing the rest efficiently.
Mixed precision training uses 16-bit floating point for most operations while maintaining 32-bit precision for critical calculations. This approach can double training speed while reducing memory usage, making it one of the most impactful LLM optimization techniques.
Model parallelism and data parallelism strategies distribute training across multiple devices efficiently. Proper parallelization can dramatically reduce training time for large models while maintaining training stability and final model quality.
Studies show that content featuring original statistics and research findings sees 30-40% higher visibility in LLM responses, making data-driven training optimization even more critical for competitive advantage.
Deployment That Scales Without Breaking the Bank
Production environments present unique challenges that don’t exist during training. You need consistent performance under varying loads, efficient resource utilization, and cost-effective scaling strategies. A well-optimized deployment can serve 10x more users with the same infrastructure costs.
Since AI Overviews launched in May 2024, businesses have seen declining organic search traffic, making efficient AI deployment strategies even more crucial for maintaining competitive visibility and cost-effectiveness.
LLM optimization in production requires different techniques than training optimization because the priorities shift from learning to serving users efficiently and reliably.
Making Inference Faster and Cheaper
Model quantization reduces numerical precision from 32-bit to 8-bit or lower while maintaining acceptable accuracy. This can reduce model size by 75% and double inference speed. It’s like compressing a high-resolution photo—you lose some detail, but it loads much faster and takes up less space.
Hardware-specific optimization tailors models to leverage specific accelerator capabilities. GPUs, TPUs, and specialized AI chips each have unique optimization opportunities that can dramatically improve performance when properly utilized.
Batch processing optimization groups multiple requests together for more efficient processing. Proper batching can improve throughput by 300-500% compared to individual request processing, making it one of the most impactful LLM optimization techniques for high-volume applications.
Scaling Smart
Auto-scaling systems monitor demand patterns and adjust resources automatically. This prevents over-provisioning during quiet periods while ensuring adequate capacity during peak times. It’s like having a smart assistant that anticipates your needs and prepares accordingly.
Load balancing distributes requests across multiple model instances to optimize response times and resource utilization. Intelligent load balancing considers model warm-up times and current load levels to make optimal routing decisions.
Resource pooling strategies share computational resources across multiple models or applications. This approach maximizes hardware utilization and reduces overall infrastructure costs while maintaining performance isolation between different workloads.
Controlling Costs
Energy consumption optimization reduces power usage through efficient algorithms and workload scheduling. This is particularly important for large-scale deployments where energy costs are significant.
Cloud resource optimization leverages spot pricing, reserved instances, and intelligent instance selection to minimize infrastructure costs. These strategies can reduce cloud costs by 40-60% without impacting performance or reliability.
Continuous monitoring systems track performance metrics and identify optimization opportunities automatically. Real-time analytics enable proactive optimization before performance issues impact users, maintaining consistent service quality while minimizing costs.
Here’s what to focus on first: implement model quantization targeting 8-bit precision, set up auto-scaling based on request volume, configure intelligent load balancing, enable batch processing for similar requests, implement caching for frequent queries, and monitor cost per query metrics religiously.
Advanced Techniques for Better Results
Advanced optimization techniques separate the leaders from the followers. These strategies require more expertise but deliver disproportionate returns on investment. Most organizations never explore these approaches, which creates significant competitive opportunities for those who do.
LLM optimization at the advanced level means understanding the subtle interactions between different system components and optimizing them together rather than in isolation. This approach often reveals optimization opportunities that aren’t visible when looking at individual components.
Smarter Prompts and Context Management
Chain-of-thought prompting guides models through logical reasoning steps, improving accuracy on complex tasks. Proper implementation can improve performance by 20-40% without additional computational costs. Instead of asking your AI “What’s the weather?”, you might say “Based on current meteorological data, provide a brief weather summary.” Same question, but the second version helps the AI understand exactly what you want.
Few-shot learning optimization selects and organizes examples within prompts to maximize learning transfer. The right examples can dramatically improve performance with minimal context usage, making every part of your context window work harder.
Dynamic context pruning removes less relevant information while preserving critical details. This technique extends effective context length and improves processing efficiency by focusing computational resources on the most important information.
A financial services company implemented dynamic context pruning for their investment advisory chatbot, automatically removing outdated market data while preserving client preferences and regulatory requirements. This reduced context window usage by 45% while maintaining compliance and improving response relevance.
Multi-Modal and Specialized Approaches
Modality-specific processing optimizes different pathways for text, image, and audio data. Each type of data has unique optimization opportunities that can significantly improve efficiency when properly implemented.
Domain-specific fine-tuning tailors models for particular industries or use cases. Specialized optimization often delivers better performance than general-purpose approaches because it can eliminate unnecessary capabilities while enhancing relevant ones.
Regulatory compliance optimization ensures models meet industry requirements while maintaining efficiency. This is particularly important in healthcare, finance, and legal applications where compliance costs can quickly spiral out of control without proper optimization.
External Memory and Retrieval Systems
External memory systems act as smart storage for your AI. Instead of cramming everything into the limited context window, you store information externally and retrieve only what’s needed for each specific query.
Retrieval-augmented generation (RAG) is the most practical implementation of this concept. Your model queries a knowledge base and pulls in relevant information dynamically, rather than trying to memorize everything during training. This approach can reduce training costs while improving accuracy and relevance.
Vector databases make this retrieval lightning-fast. They store information as mathematical representations that can be searched semantically, not just by keywords. This means your model finds relevant information even when the exact words don’t match, improving both efficiency and effectiveness.
Better Information Organization
Information hierarchy matters more than most people realize. Models process information sequentially, so the order and structure of your context directly impacts performance and efficiency.
Priority-based structuring puts the most critical information where the model pays the most attention. This isn’t just about putting important stuff first—it’s about understanding how attention patterns work and optimizing accordingly.
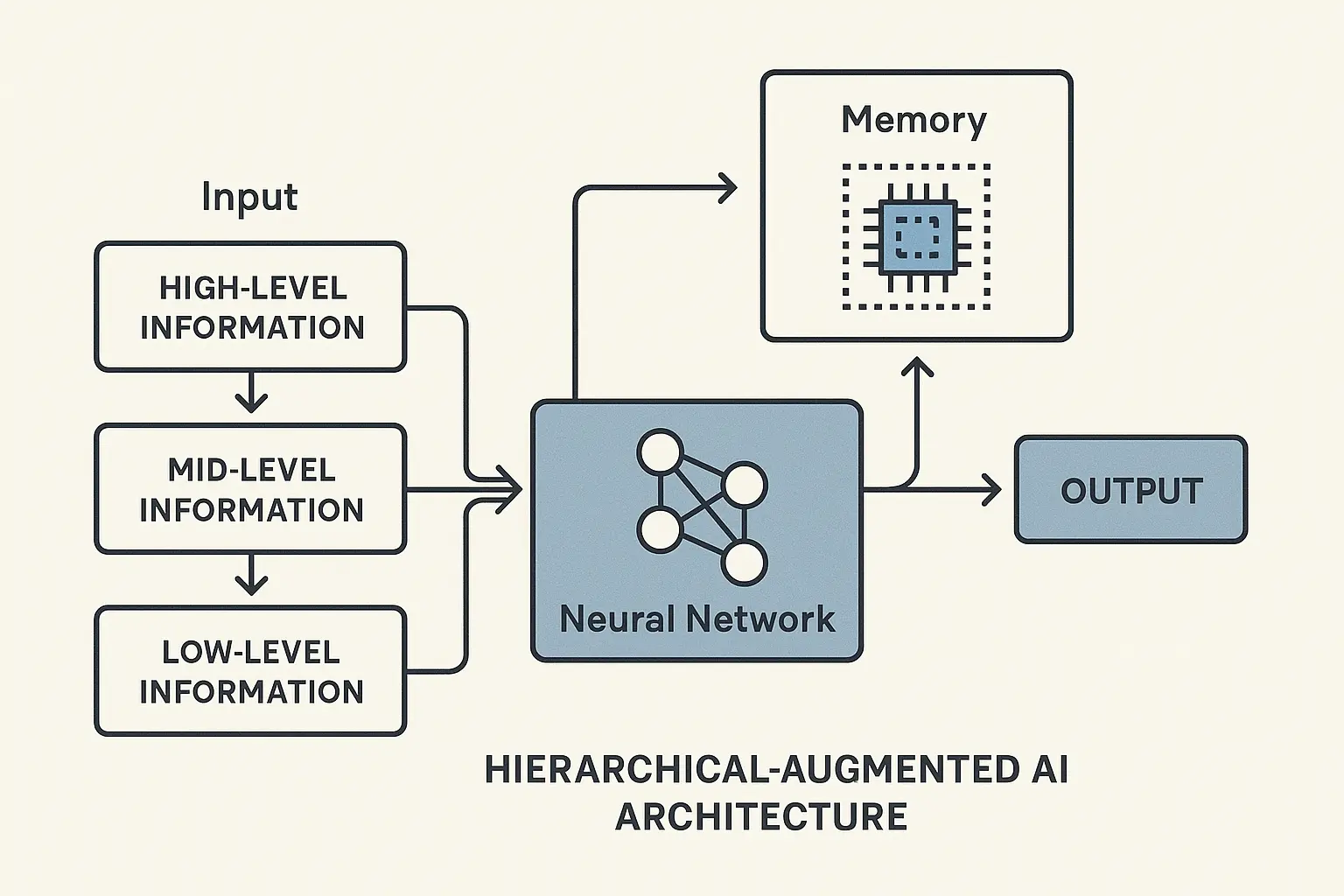
Nested information structures help models understand relationships between different pieces of information. This reduces the computational overhead needed to connect related concepts during processing, making the entire system more efficient.
Recent data shows that AI search visitors convert 4.4x better than traditional organic search visitors, making advanced optimization techniques even more valuable for businesses investing in AI-powered customer interactions.
Preparing for What’s Next
The optimization landscape is evolving rapidly. New technologies and methods emerge regularly, creating both opportunities and challenges for organizations investing in AI. You don’t need to worry about quantum computing next month, but you should understand that AI optimization is moving fast.
The techniques that work today might be outdated in two years. Build your systems to be flexible—use modular architectures that can adapt as new optimization methods emerge. The organizations that adapt quickly to new optimization paradigms will maintain significant competitive advantages.
LLM optimization will become increasingly automated and sophisticated. Understanding these trends helps you prepare for future opportunities and avoid being left behind by technological shifts.
Next-Generation Computing
Neuromorphic computing mimics brain-inspired architectures for dramatic improvements in energy efficiency. Early implementations show 100x efficiency gains for specific types of AI workloads. These chips process information completely differently than traditional processors, using spikes and timing-based computation that mirrors how biological brains work.
Intel’s Loihi and IBM’s TrueNorth chips demonstrate the potential of this approach. Early benchmarks show 1000x energy efficiency improvements for certain types of AI workloads compared to traditional GPUs. The challenge is adapting current LLM architectures to work with this hardware, but the potential energy savings make this effort worthwhile.
Quantum computing won’t replace traditional computing for LLMs, but it could accelerate specific optimization tasks. Matrix operations, optimization problems, and certain types of search could see exponential speedups. The timeline for practical quantum-enhanced LLM optimization is probably 5-10 years, but the potential impact is enormous.

Self-Improving Systems
Meta-learning systems learn how to optimize themselves, adapting to new challenges automatically. These systems could eliminate much of the manual work currently required for optimization. Instead of just optimizing a specific model, they learn how to optimize any model more effectively.
These systems could automatically discover new optimization techniques by experimenting with different approaches and measuring results. They might find optimization strategies that no human would think to try, potentially revolutionizing the entire field.
Evolutionary optimization approaches use biological principles to discover novel optimization strategies. These algorithms often find solutions that human designers wouldn’t consider, potentially uncovering entirely new optimization paradigms. They treat optimization strategies like organisms that evolve over time—successful strategies reproduce and mutate, while unsuccessful ones die out.
Reinforcement learning integration enables continuous improvement based on real-world performance feedback. These systems get better over time without manual intervention, creating self-improving optimization pipelines that adapt without human intervention.
A SaaS company implemented an evolutionary algorithm to optimize their customer support chatbot’s response generation. Over six months, the system discovered an unconventional attention pattern that reduced processing time by 35% while improving customer satisfaction scores by 18%, a combination no human engineer had considered.
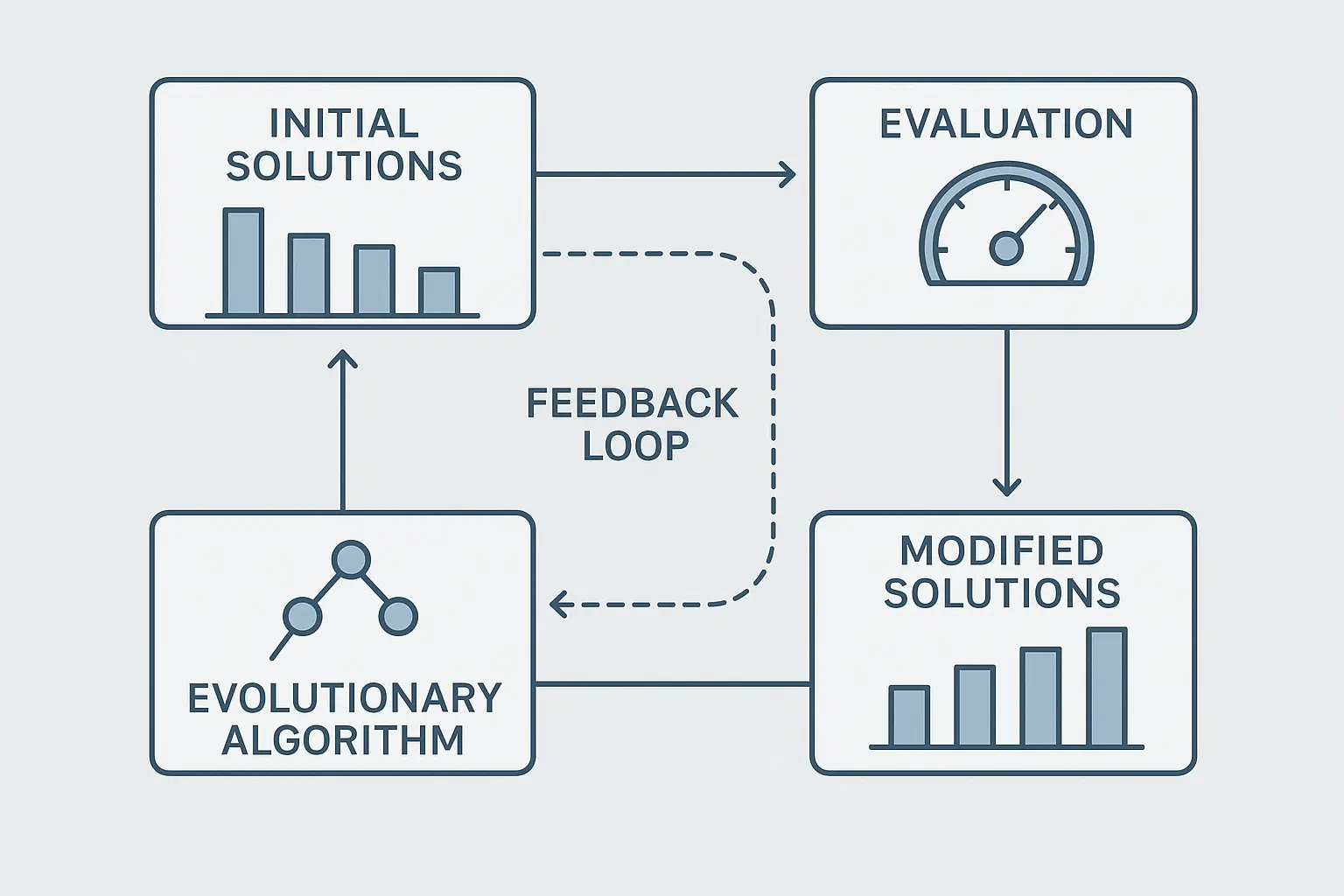
Building for the Future
Start with current best practices for architecture and training optimization. Establish baseline performance metrics and monitoring systems. Build internal expertise in optimization techniques over the next six months.
Then deploy automated optimization systems for routine tasks and experiment with emerging technologies in controlled environments. Develop partnerships with research institutions or technology vendors over the next 6-18 months.
Finally, integrate neuromorphic or quantum-enhanced processing where applicable, implement fully automated optimization pipelines, and lead industry adoption of breakthrough optimization paradigms as they mature.
Research indicates that the reward-model variant resulted in a 70% increase in average conversation length and a 30% boost in retention, demonstrating the significant business impact of advanced optimization techniques when properly implemented.
Getting Started
LLM optimization isn’t just a technical exercise—it’s a business necessity. The organizations that master these techniques will operate more efficiently, serve customers better, and maintain significant competitive advantages.
If this feels overwhelming, you’re not alone. Many companies bring in specialists to handle optimization while their team focuses on core business. The key is finding partners who understand both the technical and business sides.
Start small. Pick one optimization technique from this article and implement it this week. Measure the results. Then try another. AI optimization isn’t about perfect systems—it’s about continuous improvement.
Ready to stop overpaying for underperforming AI? With the same strategic approach that drives successful case studies across multiple industries, proven optimization methodologies can transform your AI infrastructure challenges into competitive advantages.
LLM model optimization services that combine technical expertise with business understanding ensure that every optimization decision supports your broader business objectives while delivering measurable cost savings and performance improvements.
Remember that optimization is an ongoing process, not a one-time project. The AI landscape evolves rapidly, and new optimization opportunities emerge regularly. Stay curious, keep learning, and continuously measure your results to ensure your optimization efforts deliver maximum value.
Your AI models don’t have to be money pits. With proper LLM optimization, they can become efficient, powerful tools that drive real business value while keeping costs under control. The techniques I’ve shared will help you achieve that transformation, but success depends on consistent implementation and continuous improvement.
Your future self (and your CFO) will thank you.